This article is for anyone, but is mostly aimed at people who have done some programming and now want to tackle data modelling – things like designing tables in a database.
When you start data modelling, you eventually hit the unavoidable problem that real life is big and messy. I have found two tactics to be useful for dealing with this:
- Draw a boundary around part of the world, and say that you don’t care about anything outside the boundary;
- Acknowledge that there will be some things that fall within the boundary that you won’t bother with either, because they’re special cases that would make your model more complex than you’d like.
The core of data modelling is thinking about things and the relationship between the things. So, when you start trying to make sense of a mess of data, ask two questions:
- What are the distinct and important kinds of thing that I need to worry about?
- What are the relationships between those things?
Along the way, a couple of tools will prove useful that you’re possibly already familiar with from programming:
In data modelling, the first one is sometimes expressed as one fact, one place.
We could look at an example where we create things from scratch, but I think it will be simpler for this article to improve something that already exists. Imagine a spreadsheet that holds info about cars and their owners. We could be creating a spreadsheet that is better structured, or we could be translating this into tables in a database. There’s actually very little difference, and the same principles apply. I will assume we’re creating a database, but if you prefer to think in terms of spreadsheets, then substitute sheet or tab each time you see table below.

At the highest level there are two kinds of thing, plus a relationship between them:
- Cars
- People
A way to tell that things aren’t as they should be is by reviewing this as you would review code:
- Don’t repeat yourself – there are many times that exactly the same information is given, for instance the address of someone who owns more than one car, which means that someone moving house would need the new address recording in many places;
- One reason to change – the structure of this table would need to change if we changed what we stored about: cars, people or the relationship between them.
So we will split this into a Car table and a Person table, and then link them together.
Car
- Manufacturer
- Model
- Colour
- Registration
Person
- Name
- Address
It’s nearly always a good idea to define a primary key for a table, which is mostly so that you have a defined way of referring to a given row in the table. It also helps to rule out duplicates – the database will stop a row from having the same value for its primary key as a row already in the table.
In these cases it’s straightforward – we will add CarId and PersonId. They don’t have any meaning in the outside world, but we will soon use them to help one bit of the database to refer to another bit. So the tables will now look like this (with primary keys in red):
Car
- CarId
- Manufacturer
- Model
- Colour
- Registration
Person
- PersonId
- Name
- Address
Relationships can vary, depending on how many of the things on one side of the relationship go with how many of the things on the other. We don’t usually care that it’s e.g. 16 rather than 17, and instead the important options are just: 0, 1, many.
The way into this is to simply ask questions like: Will we store information about people who have no car? Can someone own more than one car at once? Can a car be owned by more than one person at once? Will we store information about cars that no-one currently owns?
Assuming that we want to allow people to own more than one car at once, the simplest approach is to tag each car with its owner’s PersonId.
Car
- CarId
- Manufacturer
- Model
- Colour
- Registration
- OwnerId
Many cars can be tagged with a given person’s id, so one person can own many cars. A similar arrangement could exist between e.g. orders and customers – one customer could have many orders, and each order will belong to exactly one customer. Unsurprisingly, this is known as a one-to-many relationship (or many-to-one, depending on which way round it is).
The OwnerId on the Car table is called a foreign key – it isn’t a primary key but it refers to a primary key (usually on another table, in this case the Person table). I’ve marked it in blue to show its special role. Databases allow you to tell you them that this is a foreign key (and which primary key it’s pointing to) rather than just a random number. This is worth doing because it will help the database to enforce consistency – it will stop you from using a value for the OwnerId that isn’t a valid PersonId in the person table.
We might want to cope with the case of a car being owned by no-one (which I think is possible in the UK only if the car has been declared as scrap, as it will be owned by the manufacturer until it’s first sold). In this case we would make the OwnerId column nullable. This means that as well as all its normal values it can take the value null. Null is a magic value that means I don’t know or this doesn’t apply.
It’s a box you can tick for any kind of column, whether it would normally hold text, integers, or whatever. Null is a simple and consistent way of indicating that there is no value here, rather than relying on nasty things like -99999999. In real life, no apples is the same as no oranges and no sledgehammers – they are all nothing. Similarly in the database, a null integer value is the same as a null string value or a null bit of XML – they are all null.
However we will model it like this:
Car
- CarId
- Manufacturer
- Model
- Colour
- Registration
Person
- PersonId
- Name
- Address
PersonHasCar
- PersonId
- CarId
I haven’t given the fields in PersonHasCar a colour yet, but I will as soon as possible – please be patient. This structure also happens to allow a car to be jointly owned by many people – not something we particularly want, but we can live with it by ignoring that option. (We can always make things more restrictive in the code that updates the database.) This is a modelling a many-to-many relationship, when we actually have only a one-to-many relationship.
The reason why we’ll model it like this is to also record history. The previous approach didn’t allow us to record the history of cars changing hands, and people buying and selling cars – it recorded only how things are right now. To record history, we can add date ranges to the relationship table.
PersonHasCar
- PersonId
- CarId
- StartDate
- EndDate
Each row in this table shows that the relationship between car C and person P is valid for the date range shown. For cars that a person currently owns the end date is null, meaning that the relationship is open-ended. (You can use null for normal columns, and not just for foreign keys.) If an owner has agreed to sell their car next week, you could fill in the end date now with a future date if you wanted to.
If you had a car, sold it, then bought it back in the future, there would be two rows in the relationship table for the same car and person, but with different date ranges. Such rows are perfectly legal, although in this example it would be illegal for the date ranges to overlap. The example spreadsheet at the beginning doesn’t have date ranges, but I’ll pretend that we knew them somehow.
We will want a primary key for this table, and have a choice. Primary keys can be a single column, as we’ve met so far, or a compound key made of two or more columns. Remember that primary key values have to be unique across all rows in a table. Because of the case above, where someone owns a car for two or more bits of history, we can’t make a compound key of (CarId, PersonId) as this pair is shared by the two (or more) rows for the separate periods of ownership that pair the same car with the same person. So we would need to have a compound key of (CarId, PersonId, StartDate), which would be different for the different periods of ownership.
Alternatively we could treat the relationship as just another thing, like cars and people, and give each row its own Id, so that the primary key is a single column rather than many. This is where different people have different opinions, but I have found it simpler to have single column keys, so that’s what I’ll do here.
PersonHasCar
- OwnershipId
- PersonId
- CarId
- StartDate
- EndDate
So we now have the main bits of our world separated out, and linked together in the way we want. If we changed what we held about people, the car table wouldn’t care and so on. The data above can be arranged in the new tables:
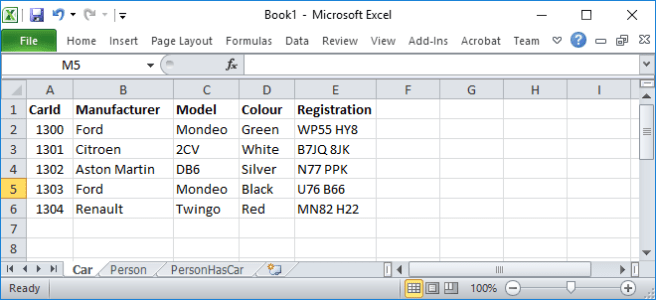
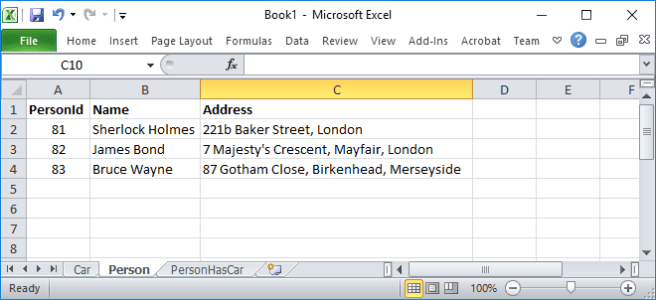

I’ve shown them as spreadsheets, just because it was an easy way to get a helpful picture. They could equally be in a database. The particular values for the ids (PersonId, CarId etc.) don’t matter, other than they need to be used consistently – the PersonHasCar table using PersonId=81 refers to the row in the Person table with PersonId=81. Defining the PersonId and CarId columns of PersonHasCar as foreign keys will mean that the database enforces this for us. If you are creating test data, I suggest that you take care with primary key values to help expose one class of bugs.
I have invented values to fill in the StartDate of the ownership, and assumed that all cars in the table are still with the same owners, so the EndDate column is null for every row.
You can see that things are tidier – we don’t have the repetition of anyone’s name and address against each car that they own. However, the main bits of the data are still messy. For instance, we still have the link between make and model of car repeated for each car, when it is really something that should be held only once. We could deal with that as follows:
Manufacturer
- ManufacturerId
- Name
Model
- ModelId
- Name
- ManufacturerId
Car
- CarId
- ModelId
- Colour
- Registration
If you’re thinking in terms of code, classes and so on, a row in the Car table now holds only the data specific to a particular instance of the Car class. Anything that is shared – details of the make, model etc. – have been separated out into other classes. There will be one instance of the Manufacturer class for Ford, one for Aston Martin etc, and these will ultimately be pointed to as appropriate by each Car instance via a Model instance.
We could carry on down this road, for example separating out people from addresses. This would be a good way of modelling a couple who live at the same address and each own one car. The address would be defined once, and there would be two people who each point at that one address by referring to its id.
Should the link between people and addresses have dates, like the relationship between people and cars? That would allow the system to record the history of where people have lived rather than just knowing where they are now. You can see how developing the data model allows you to cope with more of real life, but in doing so it gets more complicated.
The splitting up that we have been doing is called normalising the data. This is usually a good thing – it breaks the world into smaller and more easily-understood bits, and it reduces duplication and so avoids errors related to that duplication. However, if you wanted to get back to knowing all the information in the original spreadsheet, you would need to join together many tables rather than reading one. If you’re not careful that could make your code run very, very slowly.
There is more to data modelling than this – for instance, I haven’t said anything about indexes, which can make a big difference. (Adding a good index can speed things up dramatically, but having a bad index can actually slow things down more than not having the index.) However, I hope that this has taken away some of the mystery and given you an introduction.

> At the highest level there are two kinds of thing, plus a relationship between them:
Interesting that the relationships, which could change as readily as the data; were modelled on the objects. I’ve noticed everyone is doing that (like everyone is putting passwords next to logins as-if there is some fundamental relationship between the two). I prefer the joining or relationship-table approach.
Of course I’ve vastly simplified people out of the mix, but basically a table should either contain data or relationships. When you are modelling, this allows you to compose more complex models iteratively by combining with other models rather than through migrations. The reason I like to avoid migrations is that wherever possible I think adding details without risk of damage to the old ways of working almost guarantees some degree of risk mitigation. Your car-specific data would be isolated, and you just JOIN through everything that needs to be connected.
LikeLike
Wow – someone reads this! Thanks for the comment :-).
This is an instance of designing something, i.e. trying to satisfy many constraints at once. Therefore it’s likely that there’s more than one way to do it (as in the primary key for the person car table). This way of doing the relation is similar to what I’ve seen in business intelligence type applications.
As you say, the advantages of separating out relations into a separate table are that there’s more flexibility in how things are related, and also the relationships aren’t buried amongst data but are instead clear in their own tables. The disadvantages of this are that it’s another table, and also it allows a car to exist without a model. Not all relationships have the same weight, and it might be important to you to convey the strength (or it might not).
Given that it is design, I don’t think it’s wise to get dogmatic about it. If your customer, problem, team, tools or preferences constrain or encourage things into one direction rather than another, and you’re aware of and happy with the pros and cons of your approach then I think that’s a good design.
LikeLiked by 1 person
For simplicity and flexibility, it’s always best to work towards a normalised data model (logical form) which can often become the basis of the physical model too. If you read the literature on data normalisation, it will describe degrees of normalisation; usually the normalisation can finish at 3rd normal form (which is what is done here), but sometimes you need to progress a degree or two more but that’s not so common, unless a relationship has attributes which can vary over time or you need to record specific instances of a relationship.And with SQL databases this may not be practically necessary if you are willing to have non-unique primary keys on tables.
Several considerations can arise:
1/ If you need to validate that attributes (columns/fields) of an object conform to a small list of static values (a domain space), it can be tempting to set up a parent object to hold these and a foreign key relationship. IMO, this is usually a bad idea in practice as it makes the data model over-complex and inflexible. Better to do your validation with database constraints and/or a generalised code validation table. (Cleverest thing I have seen to get best flexibility and performance, ease of UX coding, and clearest metadata is to have a code validation table which have a relationship to a table which documents the tables/attributes where the codes are used. And then use this second table to generate the DDL which maintains the database constraints on the attributes, automating the maintenance of the constraints.)
2/ For performance in big databases with large number of transactions (especially batch) then sometimes the data model needs to be denormalised a bit for performance (with additional code to maintain the denormalised data consistently). This can help spread out the physical impact of single row updates, for example But only do this once you know that there is an issue (can see from low-level database stats that there is a bottleneck needing the data to be merged to reduce IO or alleviate a technical pinch point, the latter is usually database software specific)
3/ For better flexibility in the data model and code (especially if developing a package to be sold), it’s worth considering implementing a surrogate primary key in the physical model, usually based on an large integer which increments for each new row (per table or across the database) or a modestly-sized pseudo-random alpha string (validated for uniqueness), or a standardised “GUID”. This can boost performance as well (achieving some of the de-normalisation benefits from previous point). The logical primary key attributes will be present in the data model as well (with indexes and constraints) but aren’t used for table joins. This approach also simplifies cases where the logical primary key of a major parent object (with multiple layers of children) needs to be updated, which can be tricky to code and performance impacting due to the ripple effect of the change in a physical data model that is based on the logical primary keys, but less impactful using surrogate keys (which are hidden from users and should NEVER be changed except to re-mediate a corruption from a coding bug which has applied the wrong surrogate to an insert/update). I agree some data modellers dislike the surrogate concept, and it can make the SQL coding a bit less clear and longer to write as the table joins (based on surrogate fields) are less clear.
LikeLike
I forgot to mention..if you are data modelling for a system which you intend to make available to many people over the internet, and need to group data for different people together to enable collaboration (i.e. in a company) but keep private from others (i.e. other companies), then the model should consider from the start to implement a “multi-tenant” strategy. This usually means adding a column in key parts of the logical model called a “tenancy key” to allow easy segregation (and maybe database level security enforcement) within one scheme/database instance/server. The corresponding physical data model will usually have the tenant key added to all tables (to allow rows to be quickly and robustly filtered in queries, views, reports etc.). Surrogate keys are a useful adjunct for multi-tenancies as well.
At scale, a tenancy key approach with all data in one schema/database will be cheaper to scale and operate than multiple schemas/databases (one schema per organisational group). Trade off is coding complexity (which also needs to take key to include the tenancy key to not create a privacy breach between organisational groups, although some databases can automate tenancy key enforcement).
LikeLike