Introduction
There is usually a lot of testing that you could do next, but which should you do next? Which test is the most valuable? This article suggests a way of navigating through your set of tests, which has implications for which tests you should write when, when you should run them and for what tools your test set-up should give you. It shouldn’t be too hard to understand, and I hope it’s helpful. To keep things simple I will talk about just functional tests, but I think that the sample principles apply to other kinds of tests too, such as security, performance, scalability etc.
Describing tests in terms of their properties
I think that it’s worth stepping back from tests a bit, so that we’re not just motivated by a general testing = good feeling and actually start to think about how they’re different or similar. I don’t mean unit test / integration test / system test as in the pyramid of testing (although that’s useful).
Instead I think it’s useful to think of tests as supplying information. Usually, the information is to answer the question:
Is this code in the state I think it is?
which often specialises into
Is this code ready to ship?
There are at least three properties that describe how a test will supply you with its information:
- The probability that the test will discover that information (referred to as D below)
- The likely extra value that you will get from that information (V below)
- The likely cost of getting the information (C below)
The probability it will discover information is related to the question: Is your test flaky? Does it give false positives or false negatives? (For instance, it occasionally times out unpredictably.) However, it also relates to things like: How easy is it for the test to know how the code’s behaving? Does the code need to have more or better outputs, to aid testability?
The extra value can mean a few things. For instance, if there’s a bit of code that’s been well-behaved for a long time, then knowing that it’s well-behaved again today doesn’t actually give you much extra value. However, if there’s code that you’ve just touched, then knowing it is well-behaved is valuable. Cleverer people than me will probably see a link between this and information entropy.
Another thing it relates to is when you have multiple copies of the same test. This is either explicitly because of repeating due to different browsers and/or screen widths, or implicitly because e.g. logging in is a prerequisite for loads of tests (that’s maybe handled in the depths of the tests’ implementation). So if you have a list of C different test cases that you repeat for B different browsers and W different screen widths, and your login screen has suddenly lost its username field, you will probably be told this something close to C x B x W times because it will make all the tests fail. It will get boring, i.e. not valuable, after the first time!
A final thing it relates to is end user value. If you were forced to pick one part of your system that had to stop working, which part could you and your users live without? Which part would be hardest to live without? If your system includes a way for your users to give you money, that’s probably one of the most valuable parts. If your system is password-protected, knowing that your users can log in is also very valuable, as without it the whole system is blocked.
Putting the qualities together
The three qualities described above are related in some way. I’m not exactly sure how, but I think it’s along the lines of either
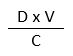 or
or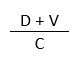
That is, the overall value of a test goes up if:
- the probability that it will find the information goes up
- the value of the information goes up
- the cost of getting the information goes down
How does this help?
Here are some examples of tests and how this way of analysing them matches your gut instinct.
Unit tests often mock loads of things, so are usually very quick and cheap to run. They don’t each deliver much value, but added together (e.g. the suite of all unit tests for your business logic) they can deliver a lot. Compare this to system tests, which usually have a much higher cost e.g. they take longer to run, need more or more specialist hardware etc.
Even if you had infinite resources, it would make sense to run all the unit tests first before running system tests. If a system test fails, then all you know is that somewhere in the code supporting that test something is wrong. If you haven’t already run the unit tests then you have a large haystack of code in which to search for the bug’s needle. However, if the unit tests have run and pass, then you know that the problem is with how the units interact, and / or or in third party code, which is likely to narrow your search space a lot.
It is important to remember that V is the extra value of a bit of information, relative to what you already know. So, the overall value of a test will change depending on what other tests have already run and whether they passed or failed.
As mentioned above, code that has been well-behaved for ages and hasn’t been touched for a while is unlikely to suddenly break, so don’t bother spending time testing it first even it’s low cost. Execute tests that exercise code that you’ve just touched first, as it’s most valuable. However, you still need to check that you haven’t pulled the rug out from under the old well-behaved code, so regression test it after the recently changed code, and before you move out to a less granular level of testing.
A general plan
It’s hard to say a single specific plan that would apply in all cases, but I’m proposing this as a starting point that you can tailor for your situation. If you have just changed some code, then tests should be run in the following order:
- Unit tests on code you’ve just touched
- Unit tests on other code that might be broken by code you’ve just touched
- Unit tests on code that’s been a problem in the past, and on code that’s the most valuable
- Unit tests on everything else
- Integration tests that include code you’ve just touched
- Integration tests that don’t include code you’ve just touched, but might be broken by code you’ve just touched
- Integration tests on code that’s been a problem in the past, and on code that’s the most valuable
- Integration tests on everything else
- Any system sanity tests, that mean you should halt testing if they fail – e.g. can log in
- System tests that include code you’ve just touched (for one browser, screen width etc. – either the combination most users use, or the one that’s easiest for the developer if there’s no clear winner among users)
- System tests that are particularly valuable
- All other system tests
- Repeat steps 9-12 for other combinations of browser, screen width etc.
I don’t think that there are many surprises here, except maybe a bit more detail within a given granularity of testing (e.g. 5 different sub-groups within unit testing). As I mentioned in the introduction, this doesn’t include things like security, performance or scalability testing. Performance and scalability testing can be quite costly due to the large amount of resources required, so I expect they would fit in towards the bottom of the list, but it would be an interesting question to see whether you do them before step 13.
If you think of the set of all tests as a 3-d space (probability of discovery, extra value, cost), then usually you would start in the corner where the first two are highest and the last is smallest. How you expand out from that corner to include the other tests will depend on your circumstances.
SpecFlow allows you to tag test scenarios, to let you filter which tests should be included in a given test run. As well as the tags that are there permanently, you could add something like @wip temporarily, so you can run just the scenarios that relate to what you’re working on right now. It’s probably worth thinking about other ways in which your test and automation tools can help you with whatever plan you settle on. For instance: Do you continue down the list if earlier tests fail?
Other things to think about
All of this ignores things outside the tests themselves, which sometimes can’t be ignored. You might be testing out a new technology, which might be easiest to do in an area of the system that you’re familiar with (even though this has been well-behaved for a while).
It might be that you’re introducing a new kind of testing, e.g. integration testing, that isn’t used anywhere in the system. It might be politically a better bet to do this on code that your team has written rather than on another team’s code, so that any hassle and false alarms due to the new kind of test are limited to your team.
Summary
Consider the information that tests can deliver, the probability that tests will discover it, the value of it, and the cost of getting it. This will help you know which tests to write next, and which tests to run next. You might have to do things to the code under test to improve some of these, to make it easier to test.
There are factors that might cause you to deviate from the plan that these things suggest, that are to do with people – what skills they have, who wrote what code etc.
