This article is in a series about computers, speech and language:
- Why are speech or language interfaces useful?
- What makes speech or language interfaces hard to create? Part 1: Overview
- What makes speech or langauge interfaces hard to create? Part 2: Speech
- What makes speech or language interfaces hard to create? Part 3: Language
- When is a speech or language interface a poor choice?
I have already described why speech and language can make for nice user interfaces, so why have they taken so long to get in common use, given that computers have been around for decades? One of the big reasons is that they are very hard to create. This post turned out to be so big that I’ve split it into three. First I will have to introduce some linguistics terms, to give some structure to what comes afterwards. Then I will talk about speech, and then about text.
A map of the land
The study of speech and text is linguistics, which is big enough that it can be split up into smaller bits. These bits sort of sit on top of each other, with the most concrete bit at the bottom and the most abstract at the top. It’s similar to the OSI networking model that breaks down the task of getting two programs, like a web browser and a web server, to talk to each other over a network.
In linguistics the layers are:
- Pragmatics (most abstract)
- Semantics
- Syntax
- Morphology
- Phonology
- Phonetics (most concrete)
I will summarise these, starting at the bottom.
Phonetics
Phonetics deals in physics-y things in speech like frequency, volume (loudness not space) and time. If you haven’t looked at a spectrogram before – a visualisation of how the frequencies in a sound change over time – it can be a revelation. (There is an excellent online thing that produces scrolling spectrograms of things like bird song and a police siren which is well worth your time.) Below is a spectrogram of the phrase nineteenth century. In a spectrogram, time goes from left to right, frequency goes from bottom to top, and intensity or volume is shown as light colours (high volume) to dark colours (low volume) like in a heat map.
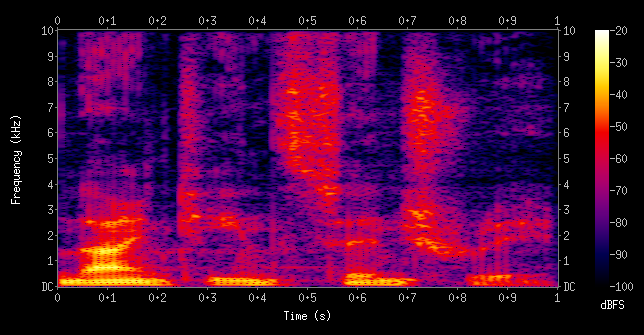
Here are some interesting parts of the spectrogram above that should be easy to find. The part that looks a bit like an anvil, centred on 0.1 seconds at the bottom of the chart is the vowel sound in nine. It’s a diphthong, which means it’s effectively two simpler vowel sounds (monophthongs) stuck together with a slide from one to the other – you can see a yellow part that slopes up to the right as the first sound changes into the second. Vowels have relatively pronounced ridges or stripes in the intensity pattern, called formants.
Then there’s the part centred around 0.5 seconds which has a big spread of frequencies rather than clear formants (the red/purple blob towards the top of the diagram) – this is the “ths” sound as nineteenth blends into century. This type of sound is called a fricative, caused by turbulence in the air that leaves your mouth, which is in turn caused by your tongue, teeth and lips arranging themselves to leave only a narrow gap for the air to go through. The turbulence means that there’s energy at many frequencies, which we hear as white noise.
Notice that there is no nice clear gap between the end of the sound of one word and the start of the sound of the next word. This is why someone speaking in a foreign language you don’t understand seems to be babbling. It’s because speakers of all languages babble (leave no gaps between words) but knowing your own language means you can interpret the sound as it flows by and split the babble up into its component sounds. Without knowledge of the language, you can’t do this splitting and all you hear is a unbroken stream of babble. (A relevant aside: the term barbarian was used by Greeks to refer to non-Greeks whose language sounded like gibberish to the Greeks and so was no different from the nonsense sounds bar-bar.)
Phonology
Phonology is where we step away from physics and pretty spectrograms, and head towards the land of symbols. It talks about what sounds a given language, dialect or accent has, and how the building blocks that this set of sounds represents can be arranged into valid words and phrases. If you are a British English speaker, it’s hard to say the r sound in French because it’s not a sound we use in British English. We have r sounds, but they’re made in a different way and sound different.
British English might not have the French r sound, but it does have two l sounds called Light L and Dark L. Light L is the sound at the beginning of leaf; Dark L is the sound at the end of ball. You might not have realised that there are two different sounds for the same letter, but there are. Try saying those words with the l sound from the other word – it will probably sound weird.
Phonology is one area where regional accents can be studied. For instance, the palettes of sounds in the English of South West England and of North East England overlap but aren’t the same.
Morphology
This is a further step up in abstraction, away from sounds and into letters and bits of words. It’s things like how a language shows that a noun is singular or plural, how it shows if an action is happening in the present, future, past etc.
It is also how a word is built up from component parts, with the components each bringing their own meaning or function. In English im- can be added to the start (but not the end) of possible to invert its meaning to impossible. It’s why think different is wrong or incomplete – different is an adjective and so can’t describe the verb think. Adding -ly to the end (not the beginning) changes the adjective into the adverb differently. (If you want to keep the original sentence with different, then add in a noun for the different to apply to, so it becomes something like think different thoughts.)
The lines between the levels are blurry, and that includes the one between morphology and syntax. In English the boy sees the dog is different from the dog sees the boy – one is being seen, the other is doing the seeing, and which is which depends on the word order. In other languages, the role a word plays in a sentence (e.g. seeing or being seen) can be shown by changing the words in some way such as their endings. In Latin, all these mean the boy sees the dog:
- puer canem videt
- puer videt canem
- canem puer videt
- canem videt puer
- videt puer canem
- videt canem puer
Syntax
Syntax is how (whole) words can be arranged into phrases or sentences using rules or a grammar. It’s why you can understand She eats a very large cake but cake large very a she eats doesn’t make much sense at all even though it contains the same words.
Computer programming languages such as C# are also defined by a grammar. The parser within a compiler uses the grammar rules built into it to turn a text file into a syntax tree in memory. The syntax tree shows how certain groups of characters form the equivalent of a word in human language (some are actual words like foreach and if, but others are symbols like ! and *). The tree then shows how these words are grouped into bigger units like statements, classes, programs etc.
In human languages and computer languages there are often words with more than one role and hence more than one meaning. In English record could be a verb meaning to make a recording, or a noun that is the product of that recording. In C, * could be a multiplication operator or a pointer de-reference.
Sometimes the context makes it obvious that only one meaning makes sense, but sometimes there is ambiguity that either has to be left unresolved, or some strategy needs to be used to deal with it. Many computer languages face the dangling else problem, and deal with it in different ways.
Semantics and Pragmatics
Semantics is about meanings. This is where things can quickly get very philosophical and / or head off into the realms of artificial intelligence.
Pragmatics is how context adds to the meaning of language. For instance if I say “It’s warm in here” it is likely that you can understand its meaning. However, two different contexts could add different extra layers of meaning:
- If it’s winter and I enter your home and say “It’s warm in here” I am likely to be paying you a compliment as a host, and thanking you for your hospitality – the inside of your home is a nice contrast to the weather outside.
- If it’s summer and I enter a hot room that you’re already in, you’re stood next to a closed window and I say “It’s warm in here” I could be implying that I’d like you to open the window. This is particularly true if we’re both British, as Brits assume everyone is fluent in sub-text and implied meaning.
Things can also get political, and look at power – who controls the meaning of a word? Can a word that used to be an insult be reclaimed by the person or group being insulted? Are some words that describe a group of people offensive if they are used by someone outside the group but acceptable for someone inside the group to use? Is the meaning of some words too bad for anyone in society to use them? If so, how do you talk about unacceptable speech in academia, the press or the criminal justice system?
Summary
This is really not intended to give you anything more than a quick scamper across the top layer of some of linguistics. The main point is to show that there are a huge number of separate but related moving parts. It takes humans ages to understand speech and language, and even adult native speakers make mistakes.
In future posts I’ll talk about the particular problems of speech and of text.

{kind=link}