This article builds on the previous article, so if you are new to the terms coupling and cohesion as they apply to software, please look at that first. In this article I’m going to look at cohesion as it applies to methods (or functions, if that’s what you call such things). Specifically, I’m going to look at long methods and methods that mix levels of abstraction. To do this I’ll use some diagrams that are similar to those in the previous article, with some differences to bring out some new details. There will also be some analogies from non-computer things to help explain.
Cohesion is fuzzy and applies at many levels
I touched on this in the previous article, but a key point behind this article is that, for me, cohesion is a fuzzy subjective qualitative thing. Worse still, there are many aspects to cohesion (although they are all variations on “belongs together”). Unlike, e.g. cyclomatic complexity, you can’t run an analyser over some code and be told by it that the code has a cohesion of 7.42. So I think it’s a concept that needs a decent understanding.
Another important point is that cohesion can apply at more than one level. You can describe the cohesion of a class, and also separately describe the cohesion of the methods in that class. For instance, the class could have high cohesion (everything in it is to do with e.g. string processing) but one of its methods could have low cohesion (it does many, separate, things to a string).
In this article I’m going to assume that we are working with a class that has high cohesion, and we’re looking at the methods within the class to assess their cohesion.
Long methods – an analogy from Google Maps’ history
First, I’ll look at long methods, using Google Maps as an analogy. When Google Maps first started being able to give you directions for a journey, the directions were complete and accurate, but hard to follow. If you wanted to go from e.g. a house in Sheffield to another house in Bristol (a distance of about 180 miles) it would quickly and accurately produce the steps you needed to take, but would present them as one long list. When I tried this just now, there are 32 steps.
If you asked a human for these directions, they would probably tell you a high-level summary, e.g.
- Get onto the nearest major road to the Sheffield house
- Cover as much distance as possible on major roads
- Get from the nearest major road to the Bristol house
Then each of these 3 chunks would be broken down into more detail, but you could understand this detail more easily because there was less of it in each chunk, and each chunk was solving a smaller problem (just part of the route, rather than the whole route). There’s the same total detail in both cases – you need to spell out all the roads to travel on – but in smaller chunks in the second version.
What’s interesting to notice is that the three chunks to the route are loosely coupled. As long as the directions on local roads within Sheffield deliver you to the same junction of the nearest major road, they can change however they like e.g. to cope with roadworks, rush hour, a local football match etc. The chunks being loosely coupled is a clue that when you combine the contents of all chunks, you end up with something with low cohesion. The parts on local roads within Sheffield don’t really belong with the parts on local roads around Bristol.
It’s worth pointing out that, despite the combined details of the chunks having low cohesion, at a zoomed-out level there is still high cohesion. Those three chunks belong together as how to get from Sheffield to Bristol. There’s nothing in there to do with e.g. a journey across Scotland. This is analogous to measuring cohesion separately at the class level and at the method level.
(Google Maps now chunks its directions up, but in the Sheffield to Bristol case breaks up the major roads chunk into two.)
Introducing the diagram
To try to translate into the world of code I’ll introduce a variation on the diagram I used in the previous article. In this new kind of diagram, a blob is a task and not necessarily a lump of code such as a method. The central blob is the overall task we’re trying to accomplish. It’s a large enough task to need to be split up into sub-tasks, which are in turn broken up further into sub-sub-tasks etc. To give a slightly more concrete example, maybe the first row of sub-tasks is something like:
- Validate inputs (violet blobs)
- Create a request based on the inputs (indigo blobs)
- Send the request to some external service (etc.)
- Wait for a response from the external service
- Handle errors in the response
- Convert the response from the external service into a form that our caller expects
- Return results to the caller
The lines show the parent / child relationship between tasks. The position of and hence distance between blobs is important. In some hand-wavy way: distance out from the centre indicates level of abstraction, and distance around a circle is to do with functional area (what the task is trying to do).
At the outer edge of the diagram are tasks or blobs that always correspond to some code. Depending on how much we group this detail into chunks, i.e. into methods or functions, the tasks towards the centre might or might not correspond to code.
One extreme case is that we just put the code for all the outer edge blobs in one big method, and then call this method. In this case we have code corresponding to the inner blob (the one big method), code corresponding to all the outer edge blobs (all the lines in the one big method), and no code for the blobs in between. The intermediate blobs would just be what we would use to describe regions of the code if we were talking through the code with someone else.
Here’s what the one big method would look like. Filled in blobs correspond to code, and empty blobs correspond to no code directly. The grey region shows blobs that belong in the same method.
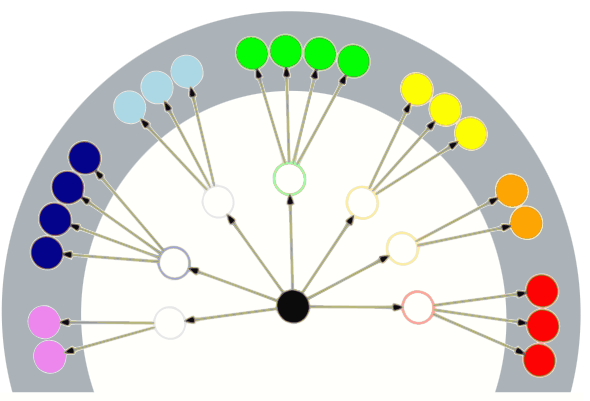
The cohesion problem of long methods
The cohesion problem with this one big method is similar to the cohesion problem with the Google Maps directions presented as one long stream of detail. At a high level, the contents of the one big method have cohesion in that they solve the same high level task. However, even though step X is related to step X-1 and X+1, because there are so many of them the first step is far from the last step, i.e. there’s low cohesion between first and last step. The details of returning results to the caller don’t depend on the details of validating the inputs, etc.
In simple and direct terms, if you drew a box around the contents of the one big method it would be very wide – there would be a big distance between its start and its end. The width is important, because someone working on this code will need to fit all of the box (all of the detail) in their head at once. This is hard.
If, instead of just being the words you’d use to describe regions in this long method, you turned the intermediate blobs into mid-level methods, then the diagram would look like this. The top-level method is just a list of 7 mid-level method calls. Each mid-level method contains a chunk of the detail that used to be in the one big method.
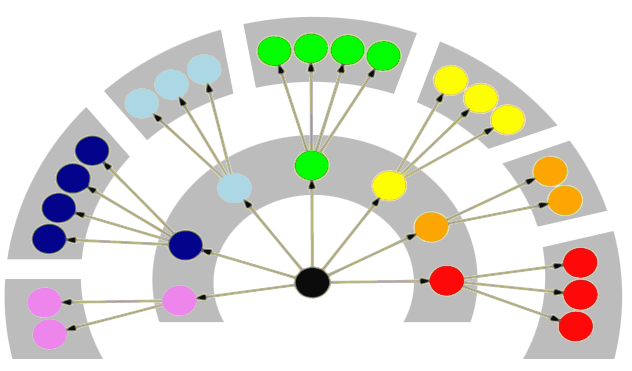
Now there are no wide methods. Each mid-level method has high cohesion – its first step is related to all the steps up till its last. E.g. all the steps in the validation method are to do with validation – there’s nothing in it to do with waiting for results. As with the maps example, these methods with high cohesion have fairly loose coupling – you can change the detail of validation without affecting waiting for results.
What’s interesting is that the top-level method (that used to be the one big method) also has high cohesion, even though it spans all the detail indirectly. This is because it deals directly only with higher-level tasks, which are conceptually closer together because they’re higher level, and there are fewer of them (again, because they’re higher level).
Occasions where long methods are justified
Please don’t read this as a pronouncement along the lines of Long Methods Considered Harmful. There are times when I think long methods are a good choice, even from a cohesion point of view.
If you must support a large set, e.g. all the possible teams in the UK football Premier League (20 teams), then you might find yourself with a method that has a switch statement with a separate case for each member of the set. (There are times when this can be avoided via arrays, where you have a member of the array for each member of the set, but this is sometimes more inconvenient than it’s worth.)
In this case, the long method is often many (20 in the case of the football example) separate mini methods welded together. Each case can be looked at fairly separately from the other cases. The role of the long method is to show that all members of the set are catered for. It’s a good idea to bury as much of the details of this into child methods, so it’s as obvious as possible that this is a method that’s addressing all members of the set.
Splitting up the long method into e.g. 5 methods that each have 4 members of the set might be possible if there’s some meaningful relationship between members of these subsets – e.g. London clubs, clubs from the North West of England etc. However, if there isn’t a meaningful way of creating subsets then I would suggest you leave it as one big method, that’s made as slim as possible via child methods. Otherwise you will have to go hunting for which method handles which member of the set.
Mixing levels of abstraction – an analogy from recipes
I’ll go into the problem of mixing abstraction levels, via an analogy based on recipes. Imagine a friend can make an amazing lasagne, and you want the recipe from them. For the purposes of this analogy, they can’t email it to you or take a photo of their hand-written notes and send that to you. Instead they have to dictate it to you over the phone. It’s a really fancy one, with two different sauces (this is the secret ingredient) as well as the cheese sauce, plus hand-made pasta made in their special way.
One way for them to describe the recipe to you is:
- Make sauce A
- Make sauce B
- Make the cheese sauce
- Make the pasta
- Assemble it
- Bake it
and then go into the detail of each part.
However, imagine that they’re really pleased with the cheese sauce as they worked really hard to get it right. So they start out as I described above, but instead of just saying “Make the cheese sauce” and then moving onto to the other bits of the summary, they go into all the detail of the cheese sauce.
By the time they’ve said “bake it” (and before they go back filling in the details of most of the steps) your head is probably swimming. There’s too much cheese sauce in your brain for you to remember all the high level steps, but also you don’t know the details of any of the other steps. This is because they have mixed abstraction levels – the high level summary has details of one of the steps.
Mixing abstraction levels
I’ll now translate the lasagne recipe summary with too much cheese sauce detail back to our tree of code-related tasks. In this case there’s one mid-level task that doesn’t have its own method (its blob is empty). Instead, all its detail is included in the top-level task. I’m afraid you’ll have to use your imagination for this one – imagine that in the second diagram above, the inner-most red blob is hollowed out, and the inner-most grey arch is extended to include the red blobs in the outer-most arch.
Notice how wide the top-level task is now. This width illustrates the difficulty of holding both the summary and some of the details in your head at once. The details don’t really belong with the rest of the summary i.e. there’s low cohesion.
Summing up
Cohesion can be measured separately at many levels at once in a code base, e.g. at the class level and again for each method in the class. Low level cohesion can suffer when lots of detail is crammed into one long method rather than the detail being chopped into chunks which are then pushed down into lower-level methods. The cohesion problem of the long method can be highlighted when it can be separated into methods that are loosely coupled.
Cohesion can also suffer when a generally high level method is missing a child method, and so is a mix of summary and details. Sometimes long methods are the right approach, if they are showing how each member of a set is being dealt with via cases in a single switch statement. However, in these cases it’s helpful to bury the detail of how each member is dealt with in other methods.
