(*Sorry, the techniques I describe don’t apply in all circumstances.)
This graph shows the time taken by 8 different ways of doing exactly the same thing: retrieving the details of 20,000 orders from a database.
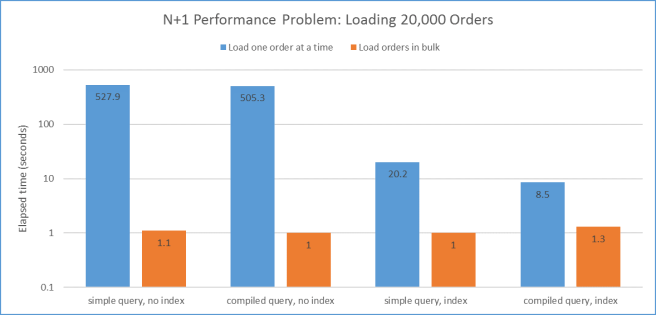
The taller the bar, the more time it took. Unfortunately I had to use a log scale because the range of values is so wide, which makes it harder to appreciate the difference. When you go up from one line to the next, duration gets 10 times bigger – for each line. Each value is the average of 5 runs, to try to get rid of any random fluctuations.
This was a C# command-line program running on the same machine as the SQL Server database it was querying, with hardly any other work going on. If the database were on a remote machine, I would expect the blue bars to be even higher relative to the orange ones than they are here.
So, what’s going on here? Why is the worst case 527 times worse than the best case? There are a few factors, and in descending order of importance they are:
- The N+1 anti-pattern for data access;
- Database indexes;
- Compiling queries.
N+1
The biggest factor is N+1, which describes a nasty trap that’s easy to fall into when accessing data. All the blue bars above have this problem, and all of the orange bars don’t.
The way I set up the database was to split each order over 2 tables. There is a summary table giving information like when the order was created, by which customer, what its status is etc. Then there is a details table giving the items within the order – for each line: which product and how many of them.
If you want all of a single order then it’s obvious that you should issue 2 queries:
- Read the row from the summary table;
- Read the 0+ rows from the details table that go with the summary row.
However, if you want to read lots of orders, the obvious thing is the wrong thing:
- Read the summary for order 1;
- Read the details for order 1;
- Read the summary for order 2;
- Read the details for order 2;
- Etc.
You could simplify this a bit, so you do one query to pull in all the summary rows, and then loop through the list of summaries to read and attach the details for that order:
- Read all the summary for all orders;
- Read the details for order 1;
- Read the details for order 2;
- Etc.
All the blue bars above share this approach. In my example there are 20,000 orders and so this results in 1 query to read all the summaries and 20,000 queries to read the details, giving a total of 20,001. This is N+1 of the title – as you can guess, even though this tidied up version is a bit better than before the tidying, it is still bad.
The problem is that you are still making N separate queries to bring in the details. When dealing with a database, the performance is often dominated by how many separate queries you send to it, rather than the total amount of data that’s shipped by the queries as a whole.
If the code behind the orange bars is avoiding this problem, what is it doing?
public static List<Order> GetAllOrdersInBulk(npoDataContext db)
{
// Get the orders as a list
List<Order> orderList = GetJustOrders(db);
// Turn the list into a dictionary (OrderId -> Order)
Dictionary<long, Order> OrdersAsDictionary = new Dictionary<long, Order>();
foreach(Order order in orderList)
{
OrdersAsDictionary.Add(order.OrderId, order);
}
// Get details for all orders, in OrderId order
IQueryable<OrderLineItem> AllLineItems = from li in db.LineItems
orderby li.OrderId
select new OrderLineItem
{
OrderId = li.OrderId,
LineItemId = li.LineItemId,
ProductId = li.ProductId,
Quantity = li.Quantity
};
// Identify a run of consecutive details for the same order, and at the
// end of the run attach it to its order
long previousOrderId = -1;
List<OrderLineItem> lineItemsForOneOrder = new List<OrderLineItem>();
foreach (OrderLineItem li in AllLineItems)
{
if (previousOrderId != li.OrderId && previousOrderId != -1)
{
OrdersAsDictionary[previousOrderId].LineItems = lineItemsForOneOrder;
lineItemsForOneOrder = new List<OrderLineItem>();
}
lineItemsForOneOrder.Add(li);
previousOrderId = li.OrderId;
}
// Don't forget to attach the last run too
OrdersAsDictionary[prevOrderId].LineItems = lineItemsForOneOrder;
// Return just the data part of the dictionary
return OrdersAsDictionary.Values.ToList<Order>();
}
The first thing it does is to get the summary records as a list. This code is shared with the N+1 version, so I’m leaving it out for clarity (particularly as it’s not the cause of the problem). To make later work easier, the list of summary records is turned into a dictionary, to make it quick to find an order from its Id. This is because in my example, some orders have 0 details, so it’s not simply a matter of sliding along two lists (summary and details) and matching things up.
Then it pulls in all the details for all orders in one go. That’s it – no other queries. So instead of 20,001 queries there are only 2. As the details are read in OrderId order, it’s not too hard to find the details that belong together and then attach them to their order record.
It’s easy to imagine situations where instead of 2 levels of data (summary -> details) there are 3. For instance, if the order had to be put into 1 or more boxes for shipping it would be order -> box -> line item. This would make the difference between the good and bad versions of the code even worse. For instance, if there were on average 5 line items per box, then the total number of queries in the bad version would be 1 + 20,000 + 5 x 20,000 = 120,001. In the good version it would be 1 query per level = 3.
Other factors
Given that the code is issuing 20,000 separate queries to bring in the details records, it’s actually doing almost identical stuff 20,000 times because the queries differ only in which OrderId they want. Instead of working out the underlying details of how to talk to the database for this query from scratch 20,000 times, you can work them out once but leave a hole to be filled each time with the particular OrderId, which is much less work. This uses System.Data.Linq.CompiledQuery.Compile() to return a delegate that you can call later with the details filled in – the database connection and the OrderId in this case.
The other thing that speeds things up for the N+1 code is to put an index on the details table, specifically on the OrderId column. This lets the N+1 code find the details for a given order much more quickly. As both versions of the code read in all the orders in the Order table, the non-N+1 code doesn’t benefit from the index as it does a simple read of the whole table. If the example read e.g. half of the rows in the Order table then the non-N+1 code would also benefit from the index. To make the code work, it would use a large in in the predicate, i.e. in SQL:
where o.OrderId in (1, 4, 88, ... , 51819, 81848)
or in LINQ:
where OrderIdList.Contains(o.OrderId)
You might have noticed that the orange bars wiggle up and down a bit. Given the log scale and the fact that they’re all close to 1, these differences are amplified. I haven’t looked into them as I don’t think they’re important, but my first approach would be many more test runs as my guess is that it’s at the level of random noise.
Summing up
Please think about N+1 when querying data (and think about Bobby Tables too). It can make a huge difference to the performance of your code. If you have access to the database, make sure that you have the correct indexes set up. Don’t forget compiling queries if you use them more than once.

Actually, Bob, your improved example is still not optimal, at least not for most modern large relational SQL database systems (and the software I work with has similar data access needs for large data sets, so this is day job bread and butter for me). A further significant performance boost on top of your optimisations will be seen, even without indexes.
Reducing the number of database round trips is good, as is reducing the number of SQL parses/compiles, although some databases will “pattern match” the SQL to work out what is replaceable and parse/compile only once, with following calls becoming a optimised fetch with just a new variable plugged in. Even without that, if you are using a SQL precompiler with a 3GL language and the right syntax the SQL will be parsed/compiled only once with a variable substitution; this may be a bit more manual when using a connectivity library like ADO or direct calls like Oracle OCI libraries. But I digress from the bigger problem, which will make the parse/compile optimisations irrelevant.
The core issue (and antipattern) is the code is doing work on the client side that the database itself can do in a much more optimised and rapid way for one parse/compile and potentially one round trip (or at worst a few fetch-only round trips), and, is consuming more client side memory than necessary to build a temporary array to join the header to the details.
I’ll assume from some comments in the post that the data consists of order header summaries (parent objects) which can have 0 or more detail rows associated (child object). Because a header can have 0 details, a database equi-join (the usual default) to link the two tables together won’t work as intended. But an outer join (syntax varies–can use keywords “outer join”, or a (+) marker on the join keys in the where clause) does the job nicely in one SQL statement, with an order by clause to have the rows return in a predictable order. When the query runs (and brings back as many rows as a time as is efficient to process) if the child object doesn’t exist, then those fields will be null. You can check for this by including a non-nullable field from the child object in the field list (e.g. child object primary key fields to parent) and test those for null, as these cannot be null normally (per usual data modelling). Can then just scroll through a (denormalised) result rowwise or in an array–the order header/summary values will be repeated once for each detail (and only once if no details are present). Most database connectivity libraries will allow you to configure to fetch blocks of rows at a time (10’s to 1000’s) after the parse/compile Only need a few specific rows or a subset? Use where clause to filter.
Indexes needed for performance? If you are filtering to a few rows with a where clause, then yes. Otherwise you are likely to find with most scaleable SQL databases that indexes will be ignored anyway as it is quicker to query all and sort-join (likely with an outer join) or hash-join to bring the rows together but throw out what is not needed. Even with a final sort. Usual rule of thumb (with Oracle anyway) that if the database thinks more than 2% of the rows of a table are potentially retrieved then it’s not worth bothering with the indexes, as the many round trip disk IO’s are slower than what is called a scatter-gather read operation to bring together a number of sequential or diverse disk blocks in one operating system IO round trip. Retrieved blocks might not be cached in database side caches but that’s not an issue. Can tune the query to force indexes to be used if you truly know different in your data (i.e. few headers with detailed lines, for example), sometimes with some databases you will have to structure the query to prevent indexes from being used inappropriately (if the query optimiser is not very good).
LikeLike
Thanks Miles – that takes it even further 🙂
LikeLike