If you write a Web API (I’m using this to mean any API that you call via HTTP, such as a REST API using the Microsoft Web API framework), the world it’s part of is:
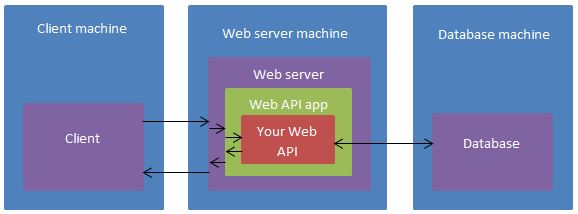
It’s likely that while you’re developing, Client machine = Web server machine = Database machine, but this might not be true in production. I’m leaving out the machine-level network stuff, so what’s left is:
- The client sends an HTTP request to the web server;
- The web server receives the HTTP request, and routes it to the Web API app or framework;
- The Web API app uses routing configuration to invoke a part of your Web API (e.g. a particular controller);
- Your Web API code has a conversation with the database (reading and / or changing its state);
- Your Web API code returns something to the Web API app (a status code, some data etc.);
- The Web API app returns an HTTP response to the web server;
- The web server returns an HTTP response to the client.
One way to test your Web API is to write a client that sends particular requests and checks the responses. SpecFlow is one way of writing a test client like this.
This form of testing is system testing – the whole system is being tested. Actually, the word system is a bit slippery – if you write a SpecFlow test client that calls the Web API then any code in the normal client, e.g. that turns the results of the Web API into HTML, will not be tested. So you’re not testing the whole system, but you are testing a meaningful and cohesive sub-system. Therefore I think that this still counts as system testing, particularly if you’re not the person who writes the normal client, i.e. your offering is just the API for someone else to use. At the very least it is integration testing, as it is testing the integration of lots of bits – the database, the web server, the Web API app and your Web API code.
Testing the whole system (however you define whole and system, as discussed above) is crucial, as this is what has to work in production.
However, it’s not the only kind of testing that would help you develop a working system in production. There are a few problems with a system test as described above, which we will try to address with other kinds of testing:
- The test (the client) keeps the code under test (your Web API code) at arm’s length – it’s in a different process, possibly on a different machine. A consequence of this is that you can’t get code coverage information for your tests. (You can’t tell which bits of code are exercised by which test or by any test.)
- There is a lot of stuff involved in each test – lots of code, lots of input state and lots of output state. This means:
- When something goes wrong you have a lot of code that could be broken, which you will need to hunt through
- A lot of code has to be working for the test to complete – bugs early on in the flow of execution could easily stop tests getting to bugs in later parts, so there is no evidence of the later-on bugs in the test results
- When something goes wrong there’s a lot of output state that you need to examine to diagnose the error
- There’s a lot of stuff that needs to be set up before the test can run
- It is relatively slow – 3 separate processes (client, web server, database) have to get involved in a choreographed dance
- In this system the only dependency is a database, but it could easily depend on something else like an external API. This is usually not under your control. If it changes, then a lot / all of your code will fail, and the errors from this could hide errors from any other bugs in your code.
- It can be hard to put the system into the correct input state for a particular test, e.g. a database transaction has failed, the whole database has died etc. As a result, this kind of test is often skipped, with the programmer thinking “Oh, that will never happen”.
Unit tests are one way to test your code with as few of these problems as possible.
This is an expanded view of your Web API code (turned around a bit from the previous diagram), showing how it’s broken into layers and classes (the blue boxes), the paths through the code (the white lines) and the connections between the classes where they call each other.

What unit testing does is test each (public) method in isolation (along with any private methods that the public method calls). Therefore:
- Any errors that a unit test finds (usually) relate to bugs in the class under test and not to other code;
- A bug in one class won’t stop the testing of other classes, even those that depend on it;
- There is only as much output state generated as the class under test can produce, which is usually smaller than for the whole system;
- There is much less state to set up per test (although the total amount of input state across all unit tests will still be large);
- The code under test, the test and the test harness (such as NUnit) are all in the same process, which speeds things up – faking the database (see below) also speeds things up;
- The code under test is freed from outside dependencies such as external APIs.
- It is easier to test the hard scenarios like a dead database (because you fake it – see below).
As the tests and code under test are part of the same process, it’s possible to gather test coverage data too.
Instead of the normal flow of execution (in at the top via an HTTP request, going all the way down to the database and back), the tests have a much shorter flow of execution. Execution starts at the top of the code under test, and stops at the bottom of the code under test. The first part is easy – the test just calls the code under test, e.g. a particular method in a class in the middle layer. The second part – stopping at the bottom of the code under test rather than going all the way down – is a bit harder and less obvious.
The way to stop execution from going down into lower-level code is to use fake or mock versions of the lower-level code. Instead of e.g. code in the middle layer calling the bottom layer to get data from the database, the middle layer will use a mock version of the bottom layer that returns a hard-coded set of data that you gave to it as part of the test set-up. Alternatively, a mock can raise a particular exception, corresponding to something like the database dying or some other nasty case.
To use mocks you need to do two things:
- Create the mocks (I know, it’s obvious)
- Get the code under test to use the mocks rather than the true versions of things
A nice way of doing the first one in C# is to use Moq. The second one is easy if the code is structured appropriately, which might not be true.
The key aspect of the code’s structure that must be correct is: A class must not resolve its dependencies by itself, but instead must rely on something outside of itself to do that.
When the top layer code needs to call code from the middle layer, the wrong thing to do is for the top layer to create its own instance of the middle layer objects. Another thing to watch out for is the use of static methods and properties. It could be fine – it’s unlikely that you will want to have an override for the value of PI in your tests – but things like DateTime.Now could easily make your tests brittle and / or a pain to set up.
A class must accept the objects on which it depends in some way – either through its constructor or via a setter. (The dependencies could either be the objects it needs, or ways of getting those objects such as a factory.) In the unit tests, mock versions of the dependencies will be passed in by the test code. In production things will be magically stitched together by a Dependency Injection framework.
These can work by having a bit of configuration code that you write that is run at or near the start of execution. The configuration code creates a look-up table: from interface name to class name. The DI framework then spots the need in your code’s constructor for an instance of an object that implements a particular interface, consults the table, creates an instance of the appropriate class, and passes it to your code’s constructor.
Using mocks in unit testing is great apart from the bottom layer. Having the bottom layer talk to a fake database is rarely useful, as there is just so little that is true and realistic in the test environment and so much fakery. For instance, knowing that the indexes are set correctly in the database is only done by running against a real database in a realistic way. You can still unit test the bottom layer, but you need a real database (possibly with test data, as controlled or set up by the test code) to test against.
If there is an external API, in general it’s a good idea to have your own code as a wrapper around it to act as a circuit breaker. This makes it easier to introduce a mock version of the external API in one place (via the wrapper) rather than having to change it each place it’s called.
This post deliberately doesn’t go into the details of dependency injection or creating mock objects as it’s intended to give the background to different kinds of testing and their different costs and benefits. It also doesn’t go into many other kinds of testing – performance, load, scalability, security, accessibility, usability etc – they are all very valuable but also beyond this article’s scope.

One thought on “Testing a Web API”