This article is part of a series: From Excel to SSIS
- Getting started
- File Save As (a kind of Hello, World! program for SSIS)
- Filtering rows
- Grouping and calculating
- Joining streams of data
0. Introduction
Over the articles in the series, we have been gradually working our way towards useful and interesting SSIS code. So far we have got to the point where we examine each row individually and do different things with different rows (write them to different output files).
While this is useful, it still means that every bit of the output has come from the input – we aren’t generating new stuff in the code. That will change in this article, where we will group the input data and calculate average values per group.
1. Recap of Excel’s grouping
We will be using a similar input file to last time. To group by Day and then calculate the averages of Number of visitors and Total value of tickets sold in Excel you need to do two things:
- Sort the data by Day.
- Define a subtotal on the data: at each change in Day, use the Average function to calculate a subtotal for Number of visitors and Total value of tickets sold.
This will produce a multi-level output, where you see a single set of totals for all the data, a set of sub-totals per group, or the group members with the sub-totals underneath.
2. What we will do in SSIS
We will calculate the sub-totals per group, based on an input file that isn’t already sorted. We will write a single output file that holds just the sub-totals per group.
3. The SSIS tools we will need
There are two new SSIS things in this article:
- The aggregate transformation, which will compute the groups and their averages;
- Setting meta data in a connection manager away from its defaults, so that the aggregate transformation can work on the data in the way that we want.
Other than that are the same things as we re-used in the last article, to support reading and writing files.
4. Re-using SSIS things you already know
Use the same techniques as in the previous two articles to create a new SSIS project that reads from a .CSV file. The contents of the CSV file are below:
Day,Date,Number of visitors,Total value of tickets sold Tuesday,01/05/2018,65,3584 Wednesday,02/05/2018,79,4840 Thursday,03/05/2018,72,4812 Friday,04/05/2018,96,8555 Saturday,05/05/2018,86,7712 Sunday,06/05/2018,126,14738 Monday,07/05/2018,68,3333 Tuesday,08/05/2018,10,100 Wednesday,09/05/2018,13,144 Thursday,10/05/2018,86,5748 Friday,11/05/2018,86,7664 Saturday,12/05/2018,115,10312 Sunday,13/05/2018,88,7205 Monday,14/05/2018,57,2539 Tuesday,15/05/2018,70,3509 Wednesday,16/05/2018,59,3614 Thursday,17/05/2018,87,6396 Friday,18/05/2018,95,9313 Saturday,19/05/2018,38,973 Sunday,20/05/2018,114,9334 Monday,21/05/2018,52,2548
The file is similar to the file for the previous article, but slightly different. For one thing, there are no errors so that this article can be simpler by not having to cope with errors. Please don’t get into the bad habit of ignoring errors!
5. The new SSIS stuff
The main new thing is the aggregate transformation, but if we used it next then it wouldn’t work. Before we can use it, we need to tell SSIS a bit more about the file being processed.
The default SSIS behaviour is to assume that each column of the file being read is text. This is fine if you want to compare it against a text string (as in the previous article), or to group by it (as this is effectively lots of string comparisons). However, doing calculations on text makes little sense, and so the aggregate transformation won’t present to us any options such as Average, which is what we want for the visitor and tickets columns.
To fix this, double click on the connection manager that you have already created for the input file, and then pick Advanced from the list on the left. Select the Number of visitors column and then change its DataType field from string [DT_STR] to four-byte unsigned integer [DT_UI4]. Do the same for the Total value of tickets sold column. Note that we could, if we wanted to, say that the Date column was actually a date, but we don’t need to for this article. There are lots of other options in the DataType list which you can explore at your leisure.

This has given SSIS a nudge so that the meta data for the file is how we want it. It will now flow through the system into the aggregate transformation, and allow us to do calculations (averages) on the last two columns. However, before it can get to the aggregate transformation, a) we will need to add it and b) first, we will need to get the changed meta data to flow into the flat file source.
When you save the changes to the connection manager, you will notice an exclamation mark in the flat file source. This indicates a mis-match in meta data – the source still thinks all the columns are strings. To sort this is quick – double click on the source, and a dialogue box will appear that says that there’s a meta data problem. Click yes to accept its suggestion, then OK on the next screen. The exclamation mark will have disappeared, indicating all is well now.
Now we can add the aggregate. Drag an aggregate transformation onto the canvas and connect it to the output of the source. Double click on it so that we can configure it.
From the Available Input Columns pane at the top, select Day, Number of visitors and Total value of tickets sold. This will create 3 rows in the pane at the bottom. Each of these rows is the configuration for an output column.
Day will default to Operation = Group by, which is what we want. For the other two output columns, set the operation to Average, and add the word Average to the start of the Output Alias value:
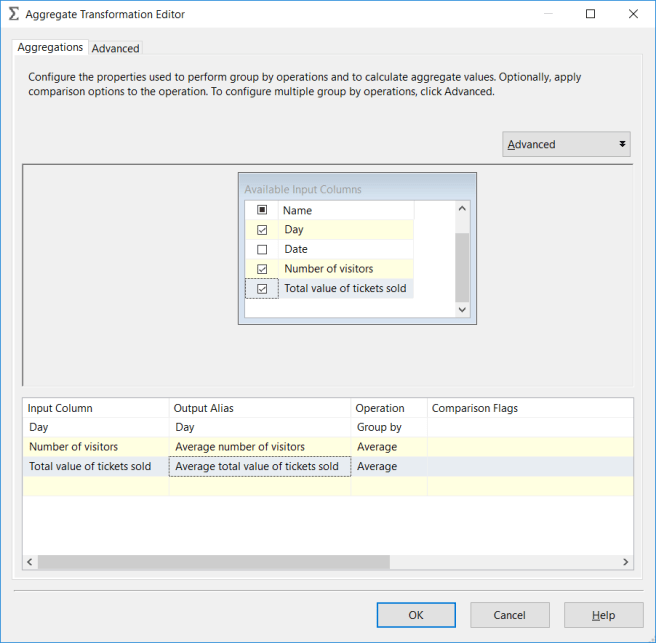
Drag a Flat File Destination onto the canvas and connect it to the output of the aggregate transformation. Create a connection manager for an output .CSV file, and give it headings that match the output alias values in the aggregate transformation.
6. Running and checking the output
When you run the SSIS program hopefully you will see something like this:
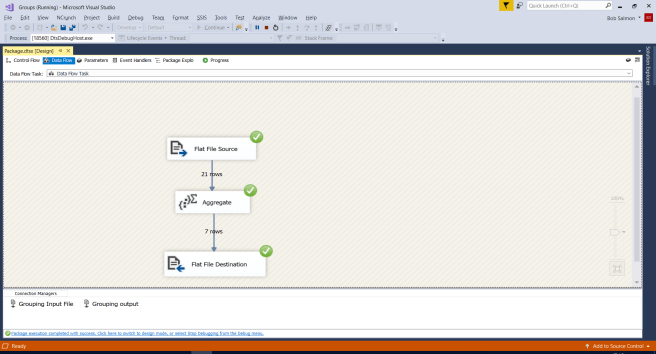
Notice that there are only 7 outputs from the aggregate transformation. This isn’t because of errors; all rows are successfully processed but they fall into only 7 different groups (the 7 days of the week).
When you open up the output file you will notice that the groups are jumbled up rather than in alphabetical or day-of-the-week order. This is because we didn’t ask for them to be sorted. I suggest that you experiment with the sort transformation between the aggregate and the flat file destination.
Also notice that we haven’t put a sort into the program before the aggregate. In Excel we needed the input file to be sorted by the column we wanted to group by, but SSIS can cope with unsorted data.
6.1 Batching and streaming
It’s a bit hard to see with such small files, but there is a fundamental difference between an operation like conditional split, and operations like aggregate and sort.
Conditional split operations are streaming operations, which means that each row can be processed independently of all other rows. This means that as soon as a row has been processed by the conditional split, it can pass its output for that row on to the next element. If we had a long string of streaming elements, the first could be processing the Nth row, while the next element in line is still processing row N-1, the element after it is still processing row N-2 etc, like the stages in a production line in a factory each processing different cars at the same time, at different stages of completion.
Aggregate and sort are batch operations, which means that they can’t send any output to the next element until they have seen all input rows – the input will get batched up by the aggregate or sort. For instance, the aggregate doesn’t know which group the last input row will go into, and so it can’t release any groups to the output in case it needs to add the last input row to one of them. Similarly, sort doesn’t know where the last input row will fit into the desired order – will it be the first output row, the last, or somewhere in between?
When you run a program in SSIS, you will see data flow through the system as far as it can. The row counts will increase, and also more and more links will spring into life and have incrementing row counts. This flowing of data stops at any batch operations – the data will build up there until it has all arrived. Then, suddenly the batch operation will start to release its output rows on to the next element, and the flow of data will resume.
7. Conclusion
We have created data for the first time using SSIS, rather than merely re-arranging existing data. We have also used a batch operation (the aggregate transform) for the first time, rather than just the streaming operations we have been using up to now (reading, writing and conditional split.)
What we haven’t done is handle more than one source of data. This is what we will cover in the next article.
