This article is part of a series: From Excel to SSIS
- Getting started
- File Save As (a kind of Hello, World! program for SSIS)
- Filtering rows
- Grouping and calculating
- Joining streams of data
0. Introduction
This article will cover another very useful chunk of SSIS – joining streams of data together. Often the value of two bits of data joined together is greater than the sum of the parts. In the article we will cover as simple a case as possible, but you could extend the idea in several ways – going for a more complicated way of joining data together, or doing this several times. For instance, if you had data from a shopping cart with customer id and product id, you could join that to both customer data and to product data.
1. Recap of joining data in Excel – VLOOKUP
One of the slightly more advanced things you can do in Excel is to join together two different bits of data. You might have one sheet showing sales orders with a product id as part of each order, and then another sheet giving details of the products you sell. You can then add the product name etc. to the sales orders by using the product id to look up a row in the products sheet, and retrieving data from the same row as the one with the matching product id.
There are two ways to do this – VLOOKUP and a combination of INDEX and MATCH. They achieve the same result – two separate bits of data that share at least one field (e.g. product id) can be joined together in some way.
This sounds like a job that SSIS could do, as we are integrating data and Integration is the I in SSIS.
What we will do in SSIS
We will build on the file we used in the previous article, and add in weather data for each day. We will produce a single output that has one row per day, showing date, ticket and visitor data and the weather.
In this really simple example we could achieve the same with a copy and paste, because there will be a one-to-one match between the two data sets. However, we could have a more complicated match and the same SSIS code would cope (possibly with some tweaks – see Running and checking the output).
The SSIS tools we will need
There are two new SSIS things we will need:
- Sorting a stream of data (which you might have already experimented as part of the previous article);
- Merge join to look up weather data for the visitor data.
There will also be the stuff you already know for reading and writing files.
Note that we will be joining data so that each row gets wider, by adding new columns from the weather stream onto those from the visitor stream. There’s another transformation in SSIS (which we won’t cover) that will make the stream longer, by adding new rows from one stream to those from the other.
Re-using SSIS things you already know
Paste the data below into a new .CSV file
Date,Weather 01/05/2018,Sunny 02/05/2018,Sunny 03/05/2018,Cloudy 04/05/2018,Cloudy 05/05/2018,Light rain 06/05/2018,Cloudy 07/05/2018,Sunny 08/05/2018,Heavy rain 09/05/2018,Heavy rain 10/05/2018,Cloudy 11/05/2018,Cloudy 12/05/2018,Light rain 13/05/2018,Light rain 14/05/2018,Cloudy 15/05/2018,Cloudy 16/05/2018,Sunny 17/05/2018,Sunny 18/05/2018,Sunny 19/05/2018,Heavy rain 20/05/2018,Light rain 21/05/2018,Sunny
We will also be re-using the input file from last time, so create flat file connection managers and elements to read both of them.
New SSIS stuff
Hopefully your data flow canvas looks something like this

The merge join transformation needs its inputs to be sorted. Both of our files happen to be sorted, but I will pretend that they’re not, so that the code is robust and so you can see the sort transformation.
Drag a sort transformation to underneath the visitors file, and connect it to the output of the visitors file. Double click so that you can configure it.
We don’t have to worry about duplicates, or about sorting by more than one field, so just tick the box next to Date.

Do the same kind of thing to sort the weather data by date. The two data streams are now ready for joining together.
Even though the merge join transformation takes two inputs, it isn’t symmetrical – the two inputs mean different things. It’s similar to the VLOOKUP of Excel. One input is treated as the main one, and values from the main input will be used to look up data in the other input. The left-hand input is treated as the main input, which is handy as we want the visitor data to be the main input in our example.
Drag a merge join transformation onto the canvas and then drag the output of the sort for the visitor data into the merge join transformation. In the dialogue box that pops up, say that it should be the left input to the merge join. Do the same for the other sort’s output – SSIS is clever enough to realise that it will act as the only remaining input (the right hand one).
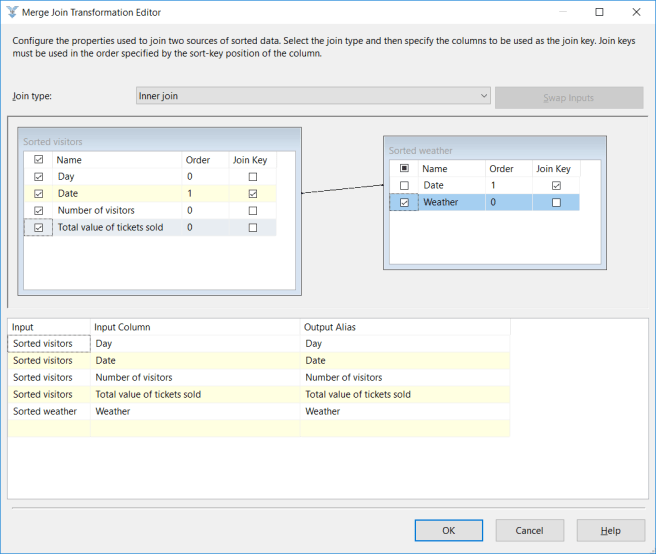
Double click on the merge join transformation to configure it. You will see the two input streams at the top of the screen, and we will configure the outputs in the bottom of the screen.
SSIS is clever enough to realise that the two inputs have a column in common called Date and has guessed that this is how the inputs can be joined. The guess is correct in our case, so we don’t need to do anything more about joining the two streams. If we needed to, we could manually configure the join key (which is what SSIS calls the columns it uses to join the two input streams).
In our example, we happen to not need to worry about the join type, but there is more discussion of this below.
We have told SSIS how to join the two streams together, but haven’t told SSIS which columns of the result we want. Select every column in the left-hand input, and just Weather in the right hand input. (You could select Date in the right-hand input instead of the one in the left, but selecting it in both would mean you would have it twice in the output.)
We now have a single stream, so as in previous examples tell SSIS to write it to a new CSV file.
Running and checking the output
When you run the program, hopefully you will see something like this

Note that we have the simplest version of joining together two bits of data. Each row in the visitor stream has exactly one match in the weather stream, which is not shared with any other row from the visitor stream. A more common simple example would have the rows in the left-hand stream sharing rows in the right-hand stream. For instance, the left-hand stream could be football players, and the right-hand stream could be information about their team – its ground, the uniform etc. The same team’s information would be copied to the rows about each of the players for that team.
Life could be more complicated (annoying) in at least two ways. First, a row in the visitor stream might fail to match any rows in the weather stream. Then we would have to decide what to do – do we send that visitor row to the output but with a gap where the match should be? In database terms this is called an left outer join. Or do we exclude rows that don’t have a match? In database terms this is an inner join, and it would mean that we would end up with fewer rows in the output than in the visitor stream. It’s often well worth knowing this explicitly, rather than just silently dropping rows. For instance you could have a separate output for just those rows with no match.
These different options are what the drop-down control at the top of the merge join transformation was about. (Its last option was a full outer join. A full outer join would be like the left outer join, but would also have weather rows that had no matching visitor row.)
Another way in which things could be more complicated is that there could be more than one matching row in the weather stream for a given row in the visitor stream. This would mean we would end up with more rows in our output than we have in the visitor stream. In some situations this is completely fine, but not always. We might do things like take the first, the one with the maximum value of some field or something else.
Conclusion
We have implemented a very useful bit of data engineering – joining two streams of data together. It comes with its own set of considerations, around what to do when the join isn’t how we would like.
The combination of filtering rows, splitting rows, grouping, and joining – as described in the previous articles – is a very powerful one. There are many more bits of SSIS to explore, but I hope that you now have a decent jumping off point for your explorations.
