My friend Ted has recently started exercising in earnest, to get fighting fit for when he can go back into schools, museums etc. to blow children’s minds about creative writing. While he exercises, he plays music from CDs to motivate him and he live streams it to Facebook for accountability. Sometimes the live stream is terminated if Facebook has detected music under copyright. Once the live stream is finished, a recording of it is available for people to watch later. If the live stream’s not terminated, then sometimes sections of the recording of the live stream are muted – again due to Facebook detecting music under copyright.
This got me thinking about how this might work. I won’t be going into the ethics of copyright, fair use etc. – just the technology side of things.
Overview
Like with my article on the security of a voice-enabled and internet-connected oven, I will:
- Do a diagram first to give a map of the land;
- Make some assumptions to do so.

This isn’t the most complex diagram in the world, but it will be used as the basis for a more complex diagram later. A single input from Ted’s phone in black is split into two paths. One path, in green, goes straight out as a live stream. The other path, in blue, is stored so that a recording of the live stream can be watched later.
Requirements
The interesting part of this is that there are two different sets of performance requirements – one for the live stream and one for the recording. (This is all on top of other very hard requirements like supporting a user base that’s a large slice of the world’s population.)
- The live stream doesn’t just pass through Facebook automatically and immediately. Some processing happens on the way (more on that below), which will delay things. This delay should ideally be less than a second, at most e.g. two seconds. Also, the delay should be regular – if frame X of the live stream is delayed by more than the delay in processing frame X+1 then the live stream will appear to pause and then skip forwards quickly, i.e. there will be jitter.
- The recording needs to be ready shortly after the live stream is finished. This doesn’t have to be as fast as the live stream – a delay of a minute or so seems to be OK. Also, as the whole recording becomes available at once, there’s no requirement for the processing of each frame to take the same time as the other frames. The whole recording can easily be delayed until all processing is finished (within reason).
There appear to be two levels of music checking – the live stream lets some music through that is caught in the recorded version. This is probably because live stream is more expensive for Facebook to check, so there are commercial considerations as well as technical ones. Maybe Facebook charges companies more for checking in real time than just checking the recording, so only the wealthy labels pay for real time checking and only for their more valuable or popular songs. Or maybe Facebook doesn’t charge but is doing this to avoid being sued by music labels. They would then vary how much checking they do when by the size of the threat based on the song and its label.
Drilling down one level in the requirements, the system needs to cope with a lot of variability. There will be variable extra noise – background noise like washing machines or someone singing along. Also the audio will come to Facebook via an unknown path – e.g. out of a stereo that has weak bass, or recorded by a phone with a dodgy mic. The path will shape the sound that Facebook receives, and it’s this shaped audio that it needs to check against a version recorded using only professional audio equipment.
High level approach
I will give the approach in a few chunks. First will be a high-level overview (in this section), then I will look at the simple music detection check, then go into what I think will be a key tool (frequency analysis), and then in the next article I will describe some algorithms that I think might work and discuss their pros and cons.
In general, to minimise the time it will take to process something, you can minimise the amount of work you do, use more or more expensive computer hardware to the work, or both. (Using more computer hardware – such as using three computers in parallel to tackle a problem that was previously tackled by only one – is known as scaling out, using more expensive computer hardware is scaling up.)
I will assume that it’s not cost effective for Facebook to do all the possible checks all of the time. So it will do work only when and how it makes sense. I think that something that will happen all the time, in real time, is a quick and crude check that the live stream contains something that might be music. If this check doesn’t detect anything that might be music, then no further resources will be spent checking this live stream, and it will pass on to viewers immediately. If the basic check says it might contain music, then the live stream is diverted to computers that can do the real time check against the shorter list of music that appears to stop live streams in their tracks. If this check doesn’t find any matches, the live stream continues to viewers. If it matches something, then the live stream is stopped.
In parallel with the live stream being checked in real time, it is copied to longer term storage so the recording can be played back later. This copying goes via checks for the longer list of music that will mute sections of the recording. Note that even though there isn’t as stringent a performance requirement on this processing as on the live stream as it goes through Facebook, this check still must be quick. I don’t think that there will be enough time between e.g. a half hour live stream finishing and its recording being available a minute later for all processing to happen at the end of the live stream. So the path heading to storage will go via checking on the way, rather than it all being recorded first and then checked later. But this checking isn’t in as much of a hurry as the real time check of the live stream.
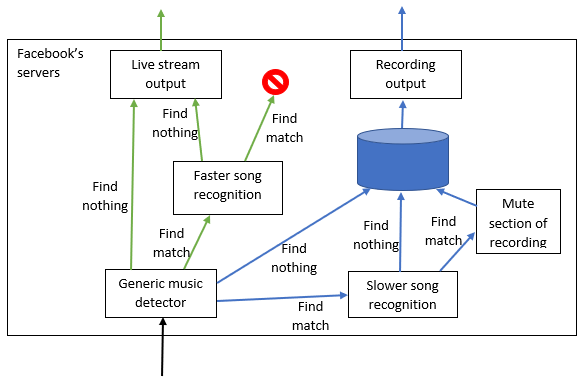
This is the same basic set-up as in the previous diagram – the one input in black comes into a shared bit of processing, after which it splits into live stream (in green) and recording (in blue). If the music detector finds no music, the live stream goes straight to the output. If the music detector finds some music, the live stream goes to faster song recognition, which will drop the stream if it matches a song it knows. A similar process happens for the recording, except the song recognition can take more time, and it mutes rather than drops the input if it matches a song it knows.
Detecting music
The does-it-contain-music check I imagine would be a simple check for parts of the sound that repeat at the right sort of frequency. Given the common range of beats per minute values for music, the audio is likely to contain some kind of repeat roughly every 0.5 – 1.5 seconds. In music with percussion, this might be the drums, but could also be rhythm guitar etc.
To check for repeating audio, you compare one copy of the music with another copy of itself that’s delayed a little. If there is no repetition, or you have the delay wrong for detecting the repetition, then the comparison will produce a fairly random result. However, if you have delayed one copy by just the right amount, then the rhythmic beats will line up across the two copies. E.g. if you have beats twice a second, then delaying one copy by half a second will make the beats of the two copies line up with each other.
When the beats line up with each other, the comparison will produce big peaks in the result when the beats happen. You need to repeat this comparison with the smallest delay you think you need (for the highest BPM you expect), all the way up to the longest delay (corresponding to the lowest BPM you expect). This can get expensive if you compare a long stretch of audio, but you only need to compare e.g. 2 seconds to find a match most of the time, and I imagine you can probably afford to do this check only every 5 seconds or so.
The nice thing about this comparison, that makes it cheaper than it might otherwise be, is that you don’t need to produce two separate copies of the signal e.g. in memory or on disk. As you aren’t changing the copies, you can re-use the one physical copy. It’s as if you point to a picture with both hands, with a little gap between them, and you compare what’s under your left hand with what’s under your right hand as you slide both hands across the image at the same speed as each other,
This process of comparing a signal with a copy of itself offset by a range of amounts is known as auto-correlation, which can produce a graph with the cool name of correlogram. When there is repetition in the signal and the delay has meant that things line up, it’s a bit like a Moire pattern. This pattern happens only because of the repetition in the underlying image that is slid over itself. If the image were something not repeating like a picture of a dog, then you would notice when the two copies were perfectly on top of each other, but otherwise there would be nothing special.

Analysing frequency and not volume
If you look at an audio signal it usually looks a bit like this

This is effectively a graph of how volume (along the vertical axis) varies over time (along the horizontal axis). For things like speech and music, it can be more helpful to transform the audio signal into something that looks like this:

This is a spectrogram, and is a graph of how intensity (colour) varies by frequency (along the vertical axis) and by time (along the horizontal axis). You can think of it as being like a series of piano keyboards stretched out in adjacent columns, with the bass notes at the bottom and high notes at the top – the different piano keys correspond to the different frequencies in the signal. The colour shows how hard to play a given key at a given time.
If you played a pure sine wave, like you used to get from a TV when it displayed the test card, the spectrogram would show a thin horizontal line – a constant single frequency. A sudden cymbal hit would produce a vertical line. This is because white noise like cymbal hits contain lots of frequencies at once. You can get a spectrogram from the volume-based graph using something like the fast fourier transform. There’s an excellent Smarter Every Day video on Fourier synthesis, which is going the other way – combining sine waves corresponding to the individual frequencies to produce a complex output such as speech or music.
Once you have this spectrogram, you then effectively impose a grid over it:
- You chop it into columns by sampling N times per second (N is likely to be 8,000 to about 44,000 to cope with the frequencies in speech or singing)
- You then chop each column into rows by dividing up the frequency range into buckets, e.g. 20-100
This gives you a grid of numbers, like in a spreadsheet. 8-44,000 times per second you get a fresh column of 20-100 numbers. Now we have reduced the audio to this set of numbers, it lets us consider some of the details of the problem.
One of the problems, which is a particular kind of background noise, is people singing along. The audio streaming through Facebook will start off as a copy of the music, with peaks and troughs in intensity corresponding to the flow of the music. If Ted’s singing is a little early or late, it will smear out peaks in audio intensity left / right in the spectrogram. If Ted is a little sharp or flat, it will smear out peaks up / down.
There’s also a more subtle problem, that happens even if Ted sang perfectly to time and pitch. The test card sound (the pure sine wave) that I mentioned earlier is not how most music sounds. The human voice and musical instruments produce a blend of frequencies and not a single frequency. There’s a base frequency of the note you’d expect plus the same note but one and more octaves up – these are the harmonics.
The same note played on a guitar and a trumpet will sound different partly because of the different blend of harmonics they produce. Similarly, unless you can impersonate someone’s singing voice, your voice will be a different blend of harmonics to theirs. So, when Ted sings along to Powerwolf, he doesn’t sound the same as Karsten Brill, even if he exactly followed time and pitch. This difference will show up as shifting intensity between the harmonics, which correspond to different frequency buckets in the spectrogram.
Summary
Leaving aside the ethics (which is a dangerous path to follow, I know) this is an interesting problem. There are hard performance targets that have to be met at scale. Even for a single user, there are hard problems to do with variability, such as background noise and difference in human singing, that make it tricky. A spectrogram can reveal helpful detail in an audio signal, that is less obvious in a simple view of how volume changes over time. In the next article I will go into some algorithms that could do the detailed matching of the audio against known songs.

{kind=link}
A friend has kindly pointed out audio fingerprinting as the way this is done, via people like GraceNote https://www.gracenote.com/music/music-recognition.
So I won’t bother going into details in a second article, because they’re probably wrong ;-). What I was going to write about were Dynamic Time Warping, Hidden Markov Models and Recurrent Neural Networks, in case you want to look those up for yourself online.
LikeLike