In this article I will talk about how to connect Azure Data Factory (ADF) to a database table. This can be surprisingly complex, so I will start with the simplest version and work towards more complex versions. I won’t go into connecting ADF to other types of data store such as APIs, blob storage etc, because this will be long enough for just database tables. The other types of data storage share the same high-level approach as the database table case, but the lower-level details are different.
The simplest version
I will assume that you have a data flow that reads from a database table and then transforms the data it receives – e.g. filtering it, grouping it etc. It then eventually writes the results somewhere, such as another database table. I’m going to ignore the details of the transformation and writing the results, plus the enclosing pipeline and factory so that I can focus on the read from the database table.
The simplest way to configure this is as follows, assuming we want to connect to the Address table in the Customer database. The thin black arrows show thing A referring to thing B in terms of configuration, rather than how the main data flows through the data flow (that’s the thick blue arrow).
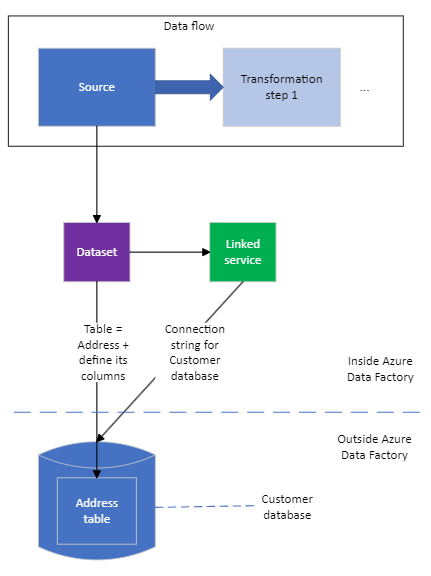
You would be forgiven for thinking that this isn’t all that simple. The data flow and the database look OK, but there are two extra objects in between them – a dataset and a linked service.
The dataset is the definition of the data that will come from the database table. This definition is a list of fields, where each field has a name and a data type (int, string etc.). This corresponds to the schema of the database table. This information allows the ADF editing tool to help you as you define the data flow – it lets ADF know what fields are available when you e.g. define a filter. This could have been defined in the source, but if there were two or more data flows or pipelines that read from or wrote to a given database table, then the information would need to be duplicated for each place it was needed. Having it in a dataset means that each place that needs to work with the table can refer to a central definition of its data.
The linked service is the definition of how to connect to the database that holds the table defined in the dataset. In the case of a SQL Server database, there are four bits of information:
- How to get to the server that holds the database
- The name of the database within the server
- User name and password to get access to the database
This could have been defined in the dataset, but if there were two or more tables being used in the same database, the connection information would need to be duplicated for each of these tables’ datasets. With a separate linked service, each data set can refer to the connection details defined in one central location. So:
- The source in the data flow refers to a dataset
- The dataset refers to a linked service
- The linked service connects ADF to the database
As things get more complicated, the data flow, source and dataset will stay unchanged. The linked service will change in the next step, but not in the last.
The secure version
What I described above will work – data will flow from the database table (assuming all the configuration is correct), and the data flow will do its work. However, there is a problem that this version will address.
Behind the scenes, the configuration for the linked service, dataset, data flow etc. will be stored in a series of JSON files. This includes the user name and password, in an unencrypted form. If you have connected the factory to version control, e.g. GitHub or Azure DevOps Repos, then the JSON file containing the user name and password (along with the other JSON files) will be copied to the version history of DevOps Repos or GitHub. This is a bad idea.
A solution to this is to use an Azure Key Vault. This is a special-purpose Azure resource for storing sensitive things such as encryption keys, API and database credentials etc. Behind the scenes, a human has to:
- Create an instance of Azure Key Vault
- Import or type the database credentials into it. A human can’t read these once they’ve been entered. The human gives
each thing its own name e.g. CustomerDatabasePassword or CustomerDatabaseConnectionString, which is how ADF will access the sensitive information later. You can also manage a key vault using Terraform. - Tell the instance of Azure Key Vault that this instance of Azure Data Factory should be given access to it.
Then, instead of entering the user name and password for the database into the ADF linked service for the database, the human will point the ADF linked service at the key vault (via its URL) and then select the relevant named secrets within it. Unfortunately it’s not quite as simple as you might expect – there’s an extra level of indirection.
One use for an ETL tool like ADF is to bring together data from many places e.g. many databases, and collate it in one central place e.g. a data warehouse. It might be that the different databases are so separate from each other that their credentials are in different key vaults. E.g. there could be a key vault for all the credentials for the purchasing department of a company, and a different key vault for the credentials for the human resources department. Therefore, each key vault that ADF talks to needs its own linked service, and then the linked service for a database connection refers to the relevant key vault linked service, rather than the database linked service referring to a key vault directly.
So the secure version looks like this:

The easily portable secure version
As before, what I’ve just described will work assuming the configuration is correct. The remaining problem is to do with portability across environments. It’s a good idea to be able to run your ADF code before it goes into production, as is good practice for e.g. C# code. It’s common to have three different environments: development, testing or staging, and production.
The different environments do different jobs: production is where the code serves its customers, development is where developers do their work, and testing / staging is where a candidate for release to production is tested in a production-like environment. It’s really important that, other than the details of things like connections to data stores, the code is unchanged as it moves between environments. This gives you confidence that e.g. the results of the tests in staging are good predictors of the code’s behaviour when it goes to production.
The different environments will include their own versions of many, if not all, of the data stores. E.g. the development environment will include a customer database, the staging environment will include its own customer database, and the production environment will contain a third customer database. (The only data stores that might be shared across environments are things like read-only files of reference data.) Therefore you want the same ADF code (i.e. the pipelines, data flows and flowlets) to talk to the development customer database when the code is deployed to development, to the staging customer database when the code is deployed to staging etc.
The easiest way to do this is to have a different key vault (or set of key vaults) per environment. The development key vault will have a secret called CustomerDatabaseConnectionString, which will point to the development customer database. The staging key vault will also have a secret called CustomerDatabaseConnectionString, but it will point to the staging customer database, etc.
The way you tell ADF which key vault[s] to point to is by adding another layer of indirection! This time it’s a global parameter. Previously, the linked service that points to a key vault specified which key vault to use via its URL. You now create a new global parameter, e.g. KeyVaultURL, to hold the URL. The key vault linked service points to this global parameter.
Note, ADF seems a little bit fussy here. Instead of simply editing the relevant text field in the key vault linked service from e.g. http://www.MyKeyVault.com to @pipeline().globalParameters.KeyVaultURL, you have to go via yet another layer of indirection. A linked service can have its own parameters, alongside the form you use to configure it. You create a linked service parameter for the key vault linked service, e.g. ls_keyvault_url, and give it the value e.g. @pipeline().globalParameters.KeyVaultURL . You then edit the config field that used to hold http://www.MyKeyVault.com to point to the linked service parameters by holding the value e.g. @{linkedService().ls_keyvault_url}.
Once you have a global parameter in the chain of layers of indirection, you can change its value as the factory is deployed in different environments. There is documentation elsewhere for how to do this e.g. via PowerShell. In the diagram below I have left out the detail within the key vault linked service (where the global parameter needs to be referred to indirectly, via a linked service parameter).

So, to achieve portability and security there are the following layers between the code (the data flow) and the table in the database:
- The dataset that describes the table’s data
- The database linked service that describes the connection to the database
- The key vault linked service that describes the connection to the key vault
- The linked service parameter on the key vault linked service that points to a global parameter
- The global parameter that points to the key vault
- The key vault that contains the connection details for the database
This is a healthy application of the fundamental theorem of software engineering:
We can solve any problem by introducing an extra level of indirection, except for the problem of too many levels of indirection.
Bonus round: Terraform
What I’ve described above absolutely works, but life gets interesting if you want to use Terraform to configure all this. (In case you haven’t come across it before, Terraform is an Infrastructure-as-Code approach to automating the management of things in the cloud, such as Azure Data Factory. I’ve written an introduction to how you can use Terraform and Azure DevOps Pipelines to run code in Azure.)
Granting permission for Azure Data Factory to access the Azure Key Vault can involve an extra level of indirection: the managed identity. Instead of saying that ADF can use the key vault, you say that a managed identity can use the key vault, and the managed identity gets associated with ADF. I won’t go into the details here, but suggest that you refer to an excellent article by Jack Roper on how to manage identities in Azure with Terraform.
