In a data pipeline (an ETL or ELT pipeline, to feed a data warehouse, data science model etc.) it is often a good idea to copy input data to storage that you control as soon as possible after you receive it. This can be known as copying the data to a staging table (or other form of data storage).
Using a staging table helps to split the problem that the pipeline is trying to solve into more, smaller, problems which can make it easier to tackle. It can also help with testability.
Note that staging here is similar to, but different from, staging in something like a staging environment as part of a CI/CD pipeline. A staging table could be present in a data pipeline whether its deployed in a development, staging or production environment. In both uses of the word, my view is that staging means something like getting something ready for the (near) future. Code goes to a staging environment to check that it’s ready to go into production. Data goes into a staging table to get it ready to be consumed by later parts of the pipeline.
Example data pipeline
In simple terms, a data pipeline can often look a bit like the diagram below. In practice it might query data from more than one source, e.g. so that it can join them together, but at its core a pipeline is often like this:

Data is read from a source, e.g. an API, transformed and then written to an output data store e.g. database table. The bulk of this article is about difficulties that stem from the source.
A source that’s not under your control
There is a big problem of testability if the source of the data isn’t under your control, e.g. it’s an API belonging to a third party such as Google or your government. How can you predict what data the API will return? If you can’t predict what data the API will return, it’s hard to do automated testing that relies on comparing actual outputs of the pipeline to expected outputs (but see my article on testing data pipelines for other forms of testing that are still possible). It’s also hard to be confident that your tests have covered all the cases that your pipeline will have to deal with e.g. very long fields, missing fields etc.
One way to handle the testability problem is to stage the data as soon as you can, in a table or other data store under your control, and then the bulk of the pipeline will read from the staging table rather than directly from the API. You will need some way of running only the second part of the pipeline (the part downstream from the staging table). This might be by splitting the original pipeline into two – a short part that calls the API and writes the data to staging, and a main part that reads from staging and processes its data – and then creating a third pipeline that strings the two smaller pipelines together end-to-end, for when you don’t want to worry about the fact that the work is split into two parts.
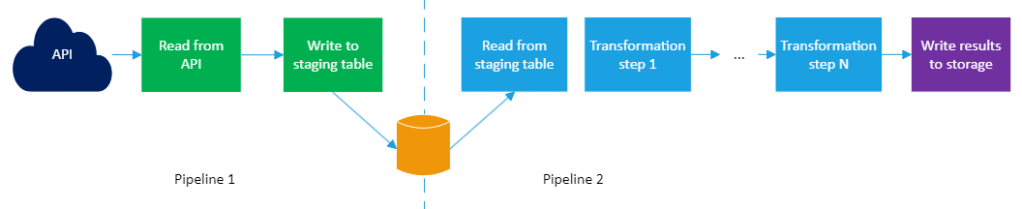
The upstream pipeline – the one that reads from the API and writes to staging – is unfortunately no more testable than before. It is still too dependent on the external source of data to be easy to test. However, the downstream pipeline is now much more testable than the corresponding section of the one big pipeline. It depends only on a table that is under your control. You are therefore free to mess about with its contents (in a testing environment, rather than in production) however you need to for testing.
The upstream part (or all of the unsplit version of the pipeline) could be tested, but with more effort and less confidence. You could implement your own fake version of the API, that is backed by e.g. a database table under your control. You would need to be able to change the part of the pipeline that talks to the API to talk to your fake version. This is a bit more effort than simply varying the staging table’s contents. It relies on the fake API’s behaviour being a close enough approximation to the real API’s to produce useful tests for the pipeline. But, on the other hand, if you had a staging table it could in theory be possible to set its contents to something that the real API would never produce in reality, so the risk is in both approaches, although I often prefer the staging table approach as it has fewer moving parts.
Splitting the problem into two parts
As well as testability improvements, there is another benefit to using a staging table. It splits the overall problem into two smaller ones – how to get the data, and then how to process it. A divide and conquer approach like this is often a good way of tackling software problems, particularly ones where you want many people to work on the solution.
This particular way of dividing up the overall problem is also a common approach in software. The code is split into two parts: a core part for the business logic, and a part for dealing with the world outside (i.e. an interface layer). As a result, it’s common for tests of the core part to be made simpler by using a dummy or mock part of the interface part. In something like C#, this mock could be something built with e.g. Moq. In the case of the data pipeline, the mock is test code that loads the staging table with canned data.
You might notice that I haven’t chopped the output end of the big pipeline into its own smaller pipeline, like I have with the input part. This is because I’m assuming that the output is simply written to somewhere under my control, e.g. a database or data warehouse, and so output isn’t adding any problems. If, instead, the output were more complex (e.g. written in batches, each with some kind of meta data) and/or involved a 3rd party (e.g. submitting the data to a government API, including the security etc. that goes with that), then it would justify being split into a separate pipeline.
You might think that the problem of getting the data is trivial and so the pre-staging bit of pipeline is trivially small. Unfortunately, this pipeline could have several problems that the main processing doesn’t care about:
- Basic access – URL, credentials, access tokens etc.
- Filtering – asking the API a specific question via filter parameters, which will involve turning values passed in from the user or higher-level pipelines into the correct form in the request to the API
- Pagination – if the API returns data in only fixed-size blocks or pages, the pipeline will need to ask for as many pages as the high-level request generates
- Extracting – the results from the API might have a lot of headers, meta data etc. as well as the main payload of data, so the results will need unpicking to get to just the payload
- Flattening – the results from the API might be encoded as JSON, which might need to be converted into a series of rows and columns ready to go into a database table, or for processing by later stages of the pipeline
Some of these might be dealt with easily thanks to the features of the ETL tool you use, but possibly not all of them. In which case the upstream pipeline will be larger and more complicated in the first diagram. This alone might make it worth splitting the one big pipeline into two smaller ones.
On top of the concerns in the list above, there are more advanced things such as error recovery. If the API returns an error that indicates the credentials are invalid or the request is incorrectly formed, the best thing for the pipeline to do is probably stop and wait for a human to fix things. If, however, the API returns an error that indicates it’s busy, it might be worth retrying later rather than being stuck until a human can help. (This is particularly true for a pipeline that’s meant to run when humans would like to not be around, such as overnight.) This would make the upstream pipeline more complicated still.
Costs of using staging tables
There is an extra table, which needs creation and management. The overall pipeline has more stages and takes longer to run. There is extra database traffic – the writes to the staging table and the reads from it.

I Take this approach with lots of things. Break them down into tiny bite-sized steps.
The other benefit of this with data is during transformation. If you have steps for each treatment or transition, then you can more easily troubleshoot.
LikeLiked by 1 person
If at all possible the externally produced code you rely on should also be staged to put it under your control; i.e “Staging input source code to improve reliability in build pipelines”.
This too has overheads, esp. at scale, so Codethink developed Lorry as an open source tool to helps us with doing this for various originating formats (from plain files, tarballs/zips, git, svn, mercurial, etc.). See: https://gitlab.com/CodethinkLabs/lorry/lorry
We use Lorry internally, and recommend our customers use it where appropriate too.
LikeLiked by 1 person