This article is about how numbers are written as words in various languages. It also has a tiny bit about functions, specifically fixed points of functions, which I use to describe how numbers work in the different languages. I speak only one of the languages below as a native, so I’ve probably made lots of mistakes – please leave a comment if you find one.
Functions
Before we get into the language stuff, I’ll take a short detour into functions as they will be useful later. In maths and computing, you can think of a function as a machine. It takes an input and produces an output. So, you could describe the function f as f(x) = x + 1. This means that f takes an input which could be any number, but we’ll call x. The output of f when given the input x is x+1. So, if the input is 300 then the output is 301 etc.
There are some functions where, whatever value you give it as input, you’ll get the same value back as the output. Examples of this are f(x) = x + 0 and f(x) = x * 1. These are known as identity functions.
Most functions aren’t identity functions – f(x) = x + 1 as we’ve already met isn’t an identity function. Within the functions that aren’t identity functions, there are some functions that have fixed points. A fixed point is a value where if you give it to the function as an input, you’ll get the same value as output. The difference between this and identity functions is the input equals the output only for special values, and all other values will produce a different output to the input. Not all functions have a fixed point.
The function f(x) = x * x has two fixed points: 0 and 1. That’s because 0*0=0 and 1*1=1. All other values when squared (multiplied by themselves) will produce a new value, e.g. 3*3=9. The function f(x) = 7 * x has the fixed point 0 because 7*0=0. 1 isn’t a fixed point because 7*1=7 rather than 1.
In the rest of this article, we’ll look at how numbers are represented as words in various languages, e.g. one, zwei etc. This is interesting, because languages have similarities but also differences to the patterns and rules they use.
As well as looking at the words, we’ll be creating a function. For a given input number:
- Write the number as words;
- Count how many characters (letters, punctuation, or spaces) are in those words.
So, in English 1 goes to one which has 3 characters, and in French 2 goes to deux which has 4 characters.
Does this function have any fixed points for the languages we look at? If so, where are they?
English
Given that this article is in English I’ll assume you’re already familiar with the words for numbers in English. In the diagram below, each blob shows a number, and each blob has one arrow leading away from it to a blob. The blob with A goes to the blob with B if B is the number of characters in the words for A. For instance there’s an arrow 1 -> 3, because 1 is written as one, which has 3 characters.
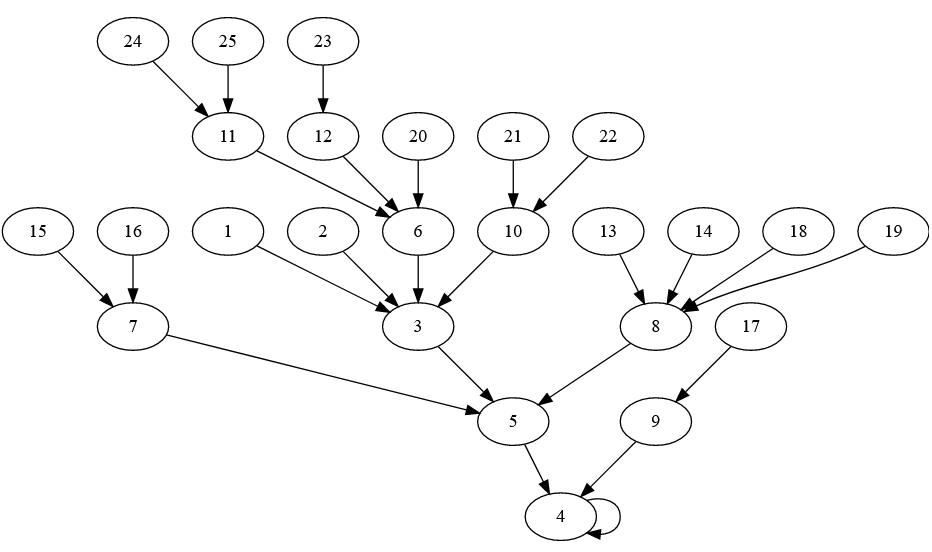
You can see from this diagram that the function we described earlier has a fixed point in English – 4. 4 is written as four, which has 4 characters.
You can also see that the numbers are divided into 3 groups:
- 1-3 – all of these have more characters in their word than the value of the number (3 is three, which has 5 characters)
- 4 – the fixed point, where the number of characters in the word equals the value
- 5+ – all numbers have fewer characters in their words than their value (25 is twenty-five, which has fewer than 25 characters)
Because of this pattern, all numbers 5 and above eventually drain down to 4. Numbers 1-3 jump from below 4 to above 4, where they join the general trend of draining down to 4.
French
French has more complicated rules than English. For instance, there is no word for 70, 80 or 90. 70 is sixty ten, 80 is four twenties, and 90 is four twenties ten. Sixty ten is one of the numbers (in English) in the song Aquarius by Boards of Canada.
French is also the first language, but not the last, where gender affects things. Is the word for 1 un or une? This matters here because they have different lengths. In all cases I’ve picked one of the genders (usually the masculine) so that there’s a single length per number but a more correct answer would show all the complexity.
Its diagram is shown below:
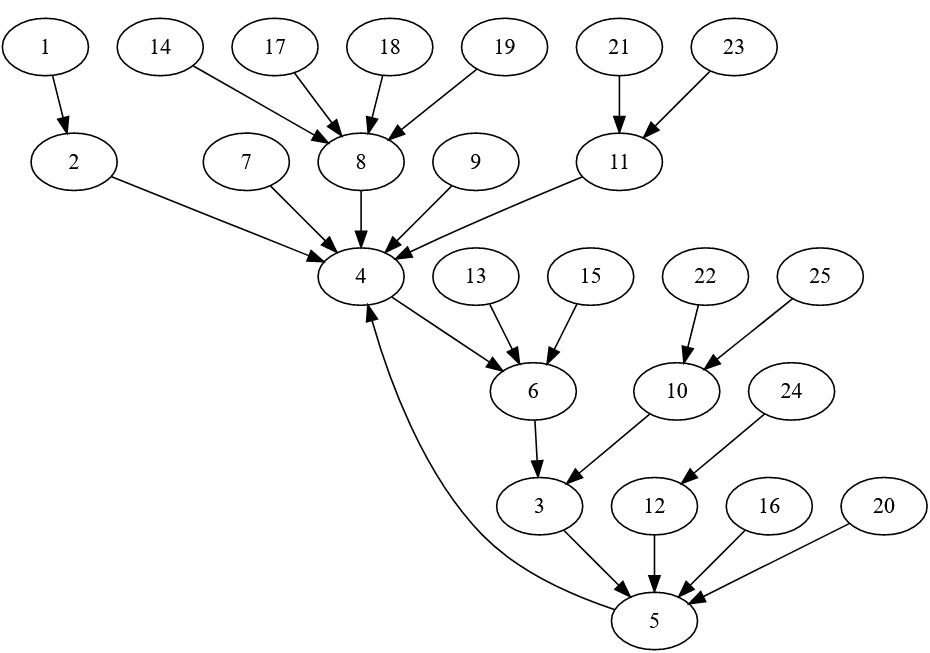
You can see that in French there is no fixed point. However, the graph does have a cycle: 4 -> 6 -> 3 -> 5 -> 4 (quatre -> six -> trois -> cinq -> quatre). Instead of draining down to a fixed point as in English, numbers drain down to somewhere on the cycle.
German
German numbers bring us to an extra idea, which is endianness. When one value is made up of bits, where the bits have an order smallest to biggest, does the smallest one go first or last? This comes from the book Gulliver’s Travels by Jonathan Swift, where Lilliputians are divided into those who eat a boiled egg starting at the big end, and those who start at the small end.
When the textual representation for a number is made up of elements that correspond to parts of the number, e.g. its digits, do the elements for the biggest part come first or last? So far, French and English have both been big endian. For instance, 1,234 is:
- One thousand, two hundred and thirty–four
- Mille deux cent trente–quatre
German is neither big endian nor little endian. It’s mostly big endian but puts units before tens. 1,234 is:
- Eintausendzweihundertvierunddreißig
Notice how the elements are combined with no spaces or dashes (but there is an and/und).
Endian crops up in other things, like writing dates. British English uses little endian, such as 25/12/2023 or 25th December 2023. It also uses big endian sometimes such as 2023-12-25. Little endian is more common for everyday use, and big endian is useful if you have dates in a computer, e.g. as the start of file names, because sorting using normal text-based sorting will also put things in date order.
This contrasts to the date format in US English which, like German numbers, is neither big nor little endian. The date mentioned above would be written as 12/25/2023. The only exception to this is the fourth of July, which is little endian.
The diagram for German is below:
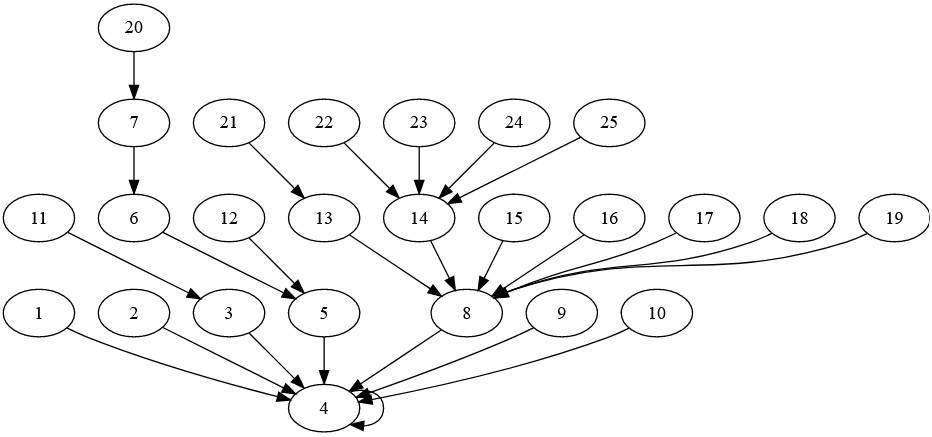
It’s identical to English – a single fixed point at 4 (vier), and no cycles. Given that English has strong historical ties to French and German, it’s interesting to see how the diagrams for English, French and German compare.
Welsh
Compared to the previous languages, Welsh numbers are incredibly regular. There are words for the numbers 1-10, but then no new words until you get to 100. To get 17 you say ten seven, and to get 53 you say five tens three. The only irregularity is the word for 10 which is deg unless you want two of them, in which case it’s ddeg. (Not only does Welsh have very regular rules for expressing numbers as words, it also has very regular rules for how to pronounce words, compared to e.g. how you pronounce ough in English.)
This is the diagram for Welsh:
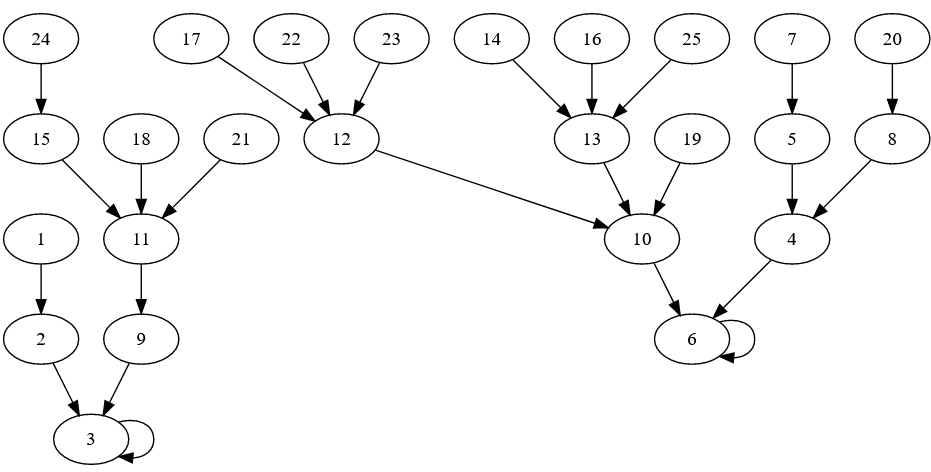
It has two fixed points – 3 and 6 (tri and chwech) and no cycles.
Old Norse
Old Norse is the reason why all the diagrams start at 1 rather than at 0. As far as I can tell, Old Norse has no concept of 0 (as opposed to the concepts of no or none). The concept of 0 was introduced to Western Europe around the 1200s. Its route was probably India, China, the Middle East and then Europe, and appears not to have entered Old Norse (but did enter the languages that evolved from it).
0 is a relatively advanced number, as it’s not part of the natural numbers. It’s not part of the world around you, which means you can’t point to, for instance, 0 trees. There’s no Roman numeral for 0, and this limitation can make arithmetic with Roman numerals easier because symbols have constant meaning rather than changing their meaning based on their position..
Another thing that Old Norse doesn’t have is symbols for numbers – numbers were written as words.
A final unusual aspect of Old Norse is that it isn’t as tied to powers of 10 as other languages are. The word hundrað is a long hundred, as it represents 120 and not 100. Similarly, þúsund is a long thousand, as it represents 1,200 and not 1,000. To represent 100 you say 10 10s (i.e. tenty) and 110 is 11 10s or eleventy. In the book The Lord of the Rings, Bilbo Baggins celebrates his eleventy first birthday, which is how you would say it in Old Norse.
This idea of long, as in long hundred or long thousand is like the number of pence in the pound in the UK in the past. Before decimalisation in 1971, a pound had 240 pence – it was made of 12 shillings, each of which was 20 pence. At decimalisation, a shilling was redefined to be 5 pence, meaning that there were 100 pence in the pound.
Endian in Old Norse seems to have been either big or little. Elements are combined with and (ok).
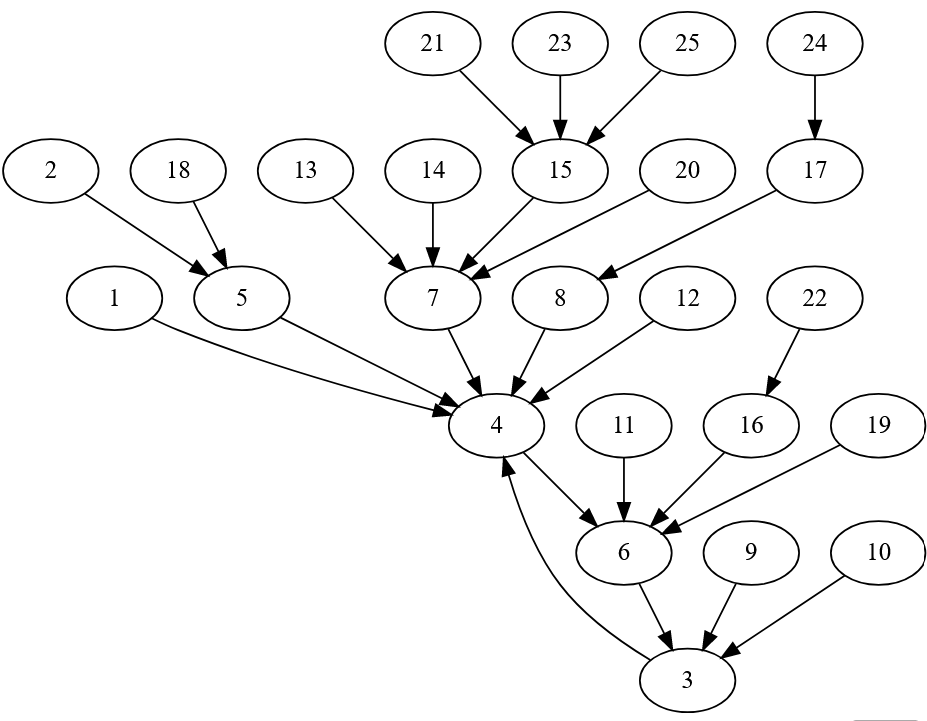
Old Norse is like French in that it has a cycle and no fixed point, but its cycle is slightly smaller than the one in French. 3 -> 4 -> 6 -> 3 (þrír -> fjórir -> sex -> þrír).
Old English
Old English isn’t the same as (modern) English, and so Old English numbers are different from modern English numbers. It has the same order as German (1234 = one thousand, two hundred, four and thirty). The word for 11 is endleofan, which literally comes from ten and one left over. You can see how modern English could have developed from Old English, but it does also seem a bit like a foreign language.
The diagram for Old English:
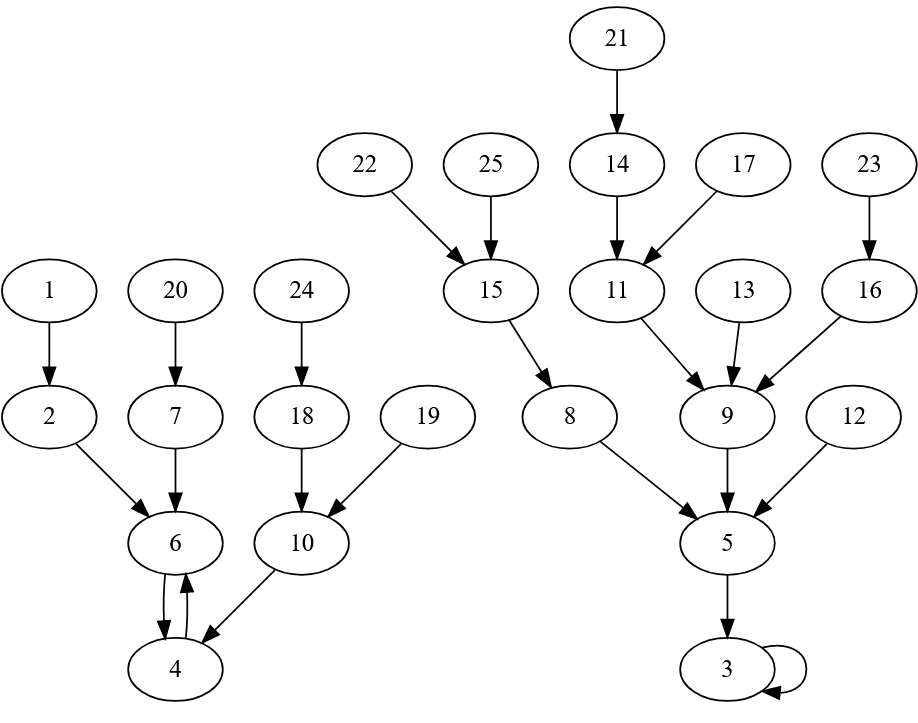
It’s the first language that has both a fixed point 3 (þrī) and a cycle 4 -> 6 -> 4 (fēower -> siex -> fēower). The word for 3 is pronounced a lot like it is in modern English, because the first character is thorn, which is pronounced like th in modern English. Thorn survived into Tudor English, although modern eyes often confuse it with Y. (So a building labelled with what looks like Ye Olde … is probably called The Old …)
Farsi
Farsi is the first non-European language, and first right-to-left language, we’ve come across. It’s a bit like English, French and German – there are unique words for 0-20, where the numbers 11-19 echo the numbers 1-9. Bigger multiples of 10 such as 30 get their own word that is based on the word for the number in the range 3-9 that says how many multiples of 10 are needed.
Hundreds get their own word that, apart from 100 and 200, is the word for a number 3-9 as a prefix to sad.
Elements are joined together by the word and (و) as many times as necessary, e.g. 123 is one hundred and twenty and three.
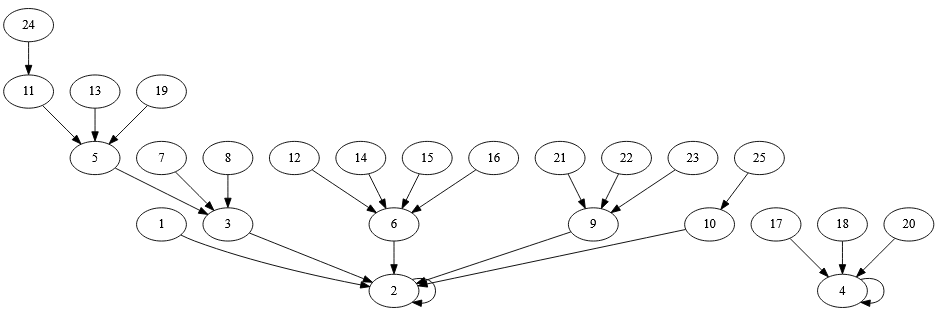
It’s like Welsh in that it has two fixed points – 2 (do or دو) and 4 (chahâr or چهار) and no cycles. Note that it matters which alphabet you use. The diagram is based on Farsi characters, and you will get a different diagram if you use non-Farsi characters (do etc.). If you use non-Farsi characters, then there’s a fixed point of 2 and a cycle 4 -> 6 -> 5 -> 4.
Looking at words for numbers
Numbers can be an interesting way to start exploring languages, because numbers are a solution to such a universal problem – how many of something do I have? They can show how languages are similar or different, how one developed from another etc. They can point at more general aspects of languages, such as how much gender affects things, when are two things different dialects of the same language or different languages?
There seems to be a general trend across all the languages in this article – the value of a number quickly gets bigger than the number of characters used to write it in words. For instance, this it the graph for modern UK English:
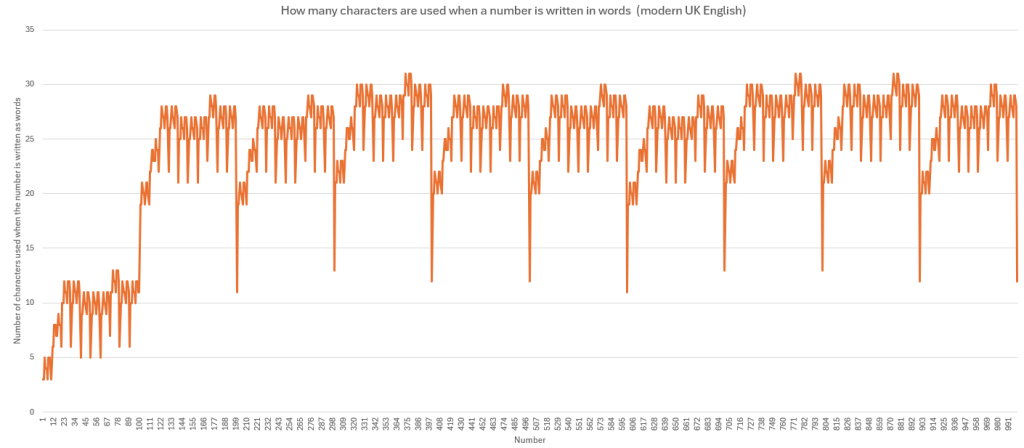
The numbers go all the way up to 1000, but the longest set of words is less than 35 characters long. Most languages (excluding Welsh) seem to have distinct words for numbers up to 20, and then assemble words to represent numbers 21 and bigger. Most languages (other than Old Norse and French) have new words for every multiple of 10 up to 100, and then new words for 100 and 1,000.
