Often in data pipelines (ETL or ELT pipelines for feeding a data warehouse, data science model etc.) we need to look up reference data that relates to the main flow of data through the pipeline. If this isn’t done carefully, there can be problems for checking how the system is running. Before the system is in production, this is a problem of testability, and once it is in production it’s a problem of observability.
In this article I’ll describe one way of doing look-ups that doesn’t incur the testability and observability problems. For simplicity I’ll assume that all data is in database tables, but it could equally be in some other kind of data store such as blob storage.
The business problem we’re trying to solve
I’ll use a specific fictitious example to illustrate the general point. Imagine we are building a data pipeline that processes information about orders for an online bakery. Each record that we’re trying to process has this information:
- Unique order id
- Order date
- Order quantity
- Product id
- Customer id
- Discount id
- Delivery address id
In database terms, this data is normalised – it doesn’t have the details of the product, customer, discount or delivery address. Instead it has a reference to data elsewhere that has this detail. For instance, the customer table will give a customer’s name, email address etc. What we want is to fetch all the relevant detail from the other tables, to make the order information much richer. In database terms, this is denormalising the data. For instance, it might end up looking like this:
- Unique order id
- Order date
- Order quantity
- Product unit price
- Product name
- Customer created datetime
- Discount name
- Discount amount
- Delivery address postcode
With this information we could work out interesting things like:
- The total undiscounted price of the order
- The price to the customer (after discount)
- How far the order is being shipped
- Is there a pattern to what our customers buy based on how long they’ve been with us?
The simple solution
Every ETL tool I have used makes it simple to look up data in table B based on matching it with data in table A. In database terms we want to join tables A and B. The join component for the ETL tools usually can join only two tables at once, so we need a series of joins one after the other like this:

The testability and observability problem
In a perfect world, this would be fine. However, in the real world, things are often not so great. If I have 100 rows in the order table, I might end up with only 80 rows in the enriched order table. Why is that? Is this OK? We could possibly work this out by checking the data in all the tables by hand, but that is slow and error-prone. This is the testability / observability problem.
The fundamental cause of the missing rows is likely to be a combination of “bad” data and the details of the join. By default, the ETL tools I’ve used will use an inner join when joining data in a pair of tables, such as the order table and the product table. That means that if the join has a row from the order table in its hand, there will be an output row only if there is a matching row in the product table. If there is no matching row, there is no output row. It doesn’t return a row where the product information is blank (null) – there is no row at all.
It might be that the row in the order table has a null product id. It might be the product id looks OK but doesn’t point to a valid product (maybe because the list of products in two places in the system are out of sync with each other), or the product id is obviously wrong e.g. “Tuesday” when it should be something like 3345. Or it might be that, instead of ids, the two tables are joined by a text field such as product name, and there are differences in spelling between the two tables.
For whatever reason the join can’t find a matching row, and because it’s an inner join it will drop the input row on the floor. We have four joins in a row, and any of them could fail to find a match. A row will make it to the output only if all the matches on the way succeed. If an order gets lost, we don’t know which join caused it.
Please note that this isn’t a fault with the ETL tool. You could implement the same thing in an SQL query, except it would probably be a single query that did all the joins at once. It would be just as inscrutible as the data pipeline as described above. You run the query and it returns 80 rows when you’re expecting 100, but the query doesn’t explain why. You have to put effort into manual debugging, such as temporarily removing each join in turn from the query, to see when each missing-but-expected row appears.
Also, it’s worth noting that joins (both in SQL queries and ETL tools) are usually asymmetric. By that I mean the two tables involved in the join don’t have equal status. You start with a main table, e.g. the order table, and then see if you can find a match in another table e.g. the product table. Imagine there are 100 rows in the order table, and 100 rows in the product table. If we start with the order table and join to the product table, in an ideal world we would expect 100 rows in the output, and the output would contain all of the input orders.
However, if all the orders in the table happened to be for lemon meringue pie, then all the outputs would contain information about lemon meringue pie. The other 99 products would not be mentioned in the output at all. This is correct in this circumstance. In database terms, there is a foreign key from orders to products, and a many to one relationship between orders and products. The join is going from the side of the relationship that’s many to the side that’s one.
Solving the testability and observability problem
Some ETL tools let you solve this simply and with other tools you need to work a little bit harder as I’ll describe below.
The simpler approach is possible when the ETL tool has two outputs from a join component – one is for data where there was a match, and one is for where there was no match. You then wire up the error output to something that will store it, which I will call a reject table. There is a choice to make for the reject table. You could have a separate reject table per place that there could be rejects (in this example, a separate reject table for each of the four joins). Or you could have fewer (possibly one) reject table, where each row is tagged with enough extra information to describe which bit of the pipeline it came from.
If you went with a separate reject table per join, the pipeline would look like this:

The more complicated approach is needed when the ETL tool’s join component doesn’t supply an error / no match output. In this case, we need to build it for ourselves. First, we need to change the join so that it’s an outer join rather than an inner one. (Strictly speaking, in database terms, we want a left outer join.) What this will do is change the behaviour when no match is found. Instead of producing no output row, it will product an output row but the columns from the other table (e.g. the product table) will be null.
So there will be an output row for all input rows, but the outputs will be a mix of good rows (where the join found a match) and bad rows (where there was no match). We then add a split component, which is something with more than one output and it picks which output a given input row should go to based on tests on the input row. (Different tools call this by different names, such as conditional routing. It’s the ETL equivalent of the switch statement in something like C#.) In our case the split will have two outputs – a good output and a reject output. A row is sent to the reject output if one of the columns from the other table (e.g. the product table) is null, otherwise the row will go to the good output.
If you drew a box around the outer join and split, it would look a built-in join that has a reject output:
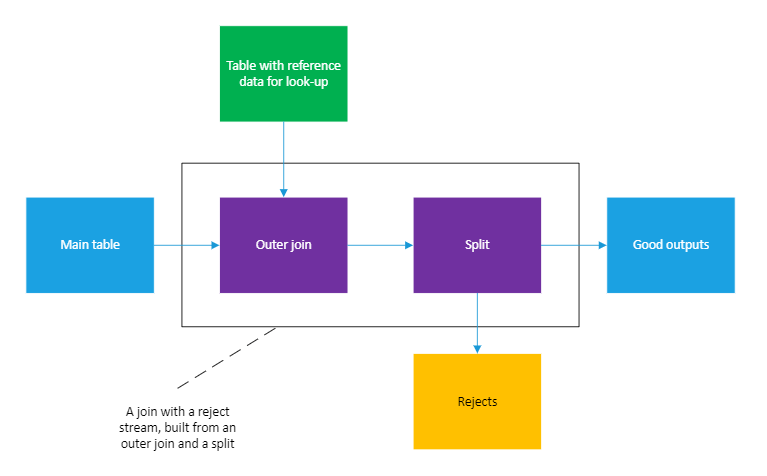
Regardless of whether we can use a built-in reject mechanism or have to implement our own, we now have a pipeline with two good properties:
- We know why data leaves the pipeline
- The pipeline downstream of the join has only good data in its inputs, so doesn’t have to worry about dealing with bad data. (This was the case before we dealt with rejects, but we haven’t made things worse. If there were no built-in reject mechanism and we simply turned the join from an inner to an outer, i.e. didn’t add a split, downstream code would have to deal with rows with missing information.)
Benefits and costs
As I described in my article on testing data pipelines this approach means that we can do automated reconciliation-based testing. We can also diagnose problems in production more easily.
The costs are: more complexity in the pipeline, and an extra table or set of tables to store the rejects.

One thought on “Improving testability and observability of look-ups in data pipelines”