This blog post came about because I remembered that there’s a place in Texas called Paris. That got me to wonder: How many countries’ capitals share a name with somewhere in the USA? It seemed to be about the right size of project to tackle, and one I could do without any coding. Like with my previous visualisation about how far bits of the UK are from other bits, I’ll go through the results and the process I used to get them. I’m not going to go into the more general data processing points, because I covered them in that previous post.
Getting the data
The list of capital cities per country was a simple Google search. This immediately hit two general processing issues: the thing being modelled is messy, and the data format is also messy. Unlike the UK, some countries have more than one capital city – Bolivia has La Paz (administrative) and Sucre (official). I chose the official one. The data also has foot notes, which I needed to remove (see below for processing).
The US place names I chose were from Wikipedia – cities, towns and villages. These were on separate pages by state, and sometimes broken into sections by size and/or alphabetically.
Processing – tools
A few years ago, Paul Boag was kind enough to have me as a guest speaker on his podcast. His podcast reflects his expertise as a digital design, UX and digital transformation consultant, but he opened it up to quite a wide range of topics. I talked about data processing using Excel and a text editor called Notepad++ (plus ETL tools like Talend).
I hoped I could use Excel and Notepad++ this time (and avoid ETL tools or coding anything) and I’m glad that this was true. They have complementary strengths, and so form a good combination.
The first stage was cleaning all the data, and then there was a second stage to try to match US place names and capital cities.
Processing – cleaning
The US place name data was often as a table in a Wikipedia page, such as the cities in New York state. I was interested in only one column of this data, and wanted just its text without any formatting, hyperlinks etc.
To get just one column was straightforward: copy the whole table, paste it into an Excel worksheet, and then select just the column I wanted.
This data sometimes needed further cleaning, such as removing links to footnotes. This was a job for Notepad++, so I pasted the column of names into a new document there. Then I used find and replace using a combination of regular expressions and an empty value in the replace field, which I’ll now explain.
The stuff I wanted to remove (the foot note and any white space around it) could be described using the regular expression “\s*\[.*\]\s*$”. A complete explanation of regular expressions is beyond the scope of this post, and I refer you to the podcast episode for some pointers. However, I’ll explain this regular expression as an example. The most important part of this expression happens to be the $, so I’ll start there and then work left.
The $ is a magic character that matches the end of the line, rather than any normal characters in the line. So, this anchors everything to the end of the line. Immediately before the end of the line there must be \s* which is 0 or more (the *) white space characters (the \s) – space, tab etc. The zero or more is the most flexible modifier in regular expressions, and it just to cope with there possibly being random spaces at the end of the line.
I’ll do the next three bits together (the \[.*\]). A pair of square brackets normally has a special meaning in regular expressions, which I don’t want here as I want to literally match square brackets. To stop the special meaning, I have to add the \ character (which acts as an escape character).
In between the square brackets I match .*. . will match any single character, and the * is the modifier we saw earlier on \s* and has the same meaning – 0 or more of them. So .* will match 0 or more of any character. If I wanted to be bullet-proof I might change this to match on 0 or more copies of any character that isn’t ], but matching any character is good enough for me and is simpler. This means that \[.*\] will match square brackets with anything inside it.
Finally (at the start of the regular expression) is another \s*, to mop up any spaces after the place name but before the foot note. The whole thing will therefore match the footnote itself, plus any leading or trailing white space, as long as this is all at the end of the line.
As you might have gathered, regular expressions can be hard to write and read, and are often a balancing act between matching too much and not matching enough. My advice is to start with small stuff and gradually add complexity.
Notepad++ has a regular expression mode to its find and replace function, and so I put the regular expression above in the Find field, and left the Replace field empty. This meant that each time it found a foot note (text that matched the regular expression in the Find field) it would replace it with nothing i.e. delete it.
One final bit of cleaning I did was back in Excel, which was to sort the US place names alphabetically. This wasn’t essential, but would speed things up later.
Processing – matching
I now had clean data to work with – a list per state of place names, and a list of capitals. I put these into separate sheets in an Excel workbook. On the capitals worksheet, I had the capitals as the first column acting as labels for rows. I then added a column heading next to this for each state. So, the cells in this table pair up each state and each capital. I then used a formula based on VLOOKUP to search for the capital city in the list of place names on that state’s worksheet. E.g.
=IFNA(VLOOKUP(CONCAT($K$1,$A178),Alabama!$A$1:$A$9999,1,FALSE),"")
A full introduction to Excel formulae and VLOOKUP is beyond the scope of this article, and there’s lots online to help you. However, some key points:
- If VLOOKUP fails to find what you asked it for, it returns the magic value NA. IFNA catches this and in this case will replace it with empty string.
- The CONCAT is because I wanted to look for the capital itself, but also prefixed with “New “, “North “, “South “, “East “ and “West “. So I created a cell to store a prefix (K1), and repeated the matching process with this empty or with the 5 prefixes I mentioned.
I could have tried more prefixes and some suffixes too, as e.g. the UK city Manchester would match Manchester by the Sea. However, I found matches with no prefix and “New “ but not with any of the other prefixes, and I was pleased enough with the results this gave, so I didn’t explore further.
Displaying the results
I thought a little about how to display the results. I wanted something more than just a table of numbers, but didn’t want to spend loads of time on something beautiful or with loads of detail. A bit of Googling delivered a JS library called DataMaps, that builds on D3. It doesn’t do absolutely everything map-related, but seems to give a quick way of doing choropleth maps. You just put your data as a JS array indexed on country (or US state) code. The last thing was working out the colours, and I cheated by doing this semi-manually via an online tool that generates N colours in between the two colours you specify.
There are three maps, although two are just zoomed in or out versions of each other:
- A map of US states, showing how many countries’ capitals can be found in that state
- A map of the world (or just Europe), showing how many times each country’s capital occurs somewhere in the USA.
The nice thing about DataMaps is it’s quite easy to display data in mouse-overs, so I didn’t bother doing a key to explain the colours.
The results
The pictures below are static snapshots, and clicking on them will take you to the interactive versions.
I’ll start with the countries maps. It’s not really a surprise that most of the countries whose capitals show up in the USA are either countries from which settlers came from (UK, Germany, France), or countries with a celebrated past (Egypt, Greece). There are some spurious results, such as Guyana – there are 17 Georgetowns in the USA. I think this is correlation rather than causation. My guess is that both Guyana’s capital and the US places are independently named after someone called George, e.g. King George III of the UK, rather than one place being named after another place.
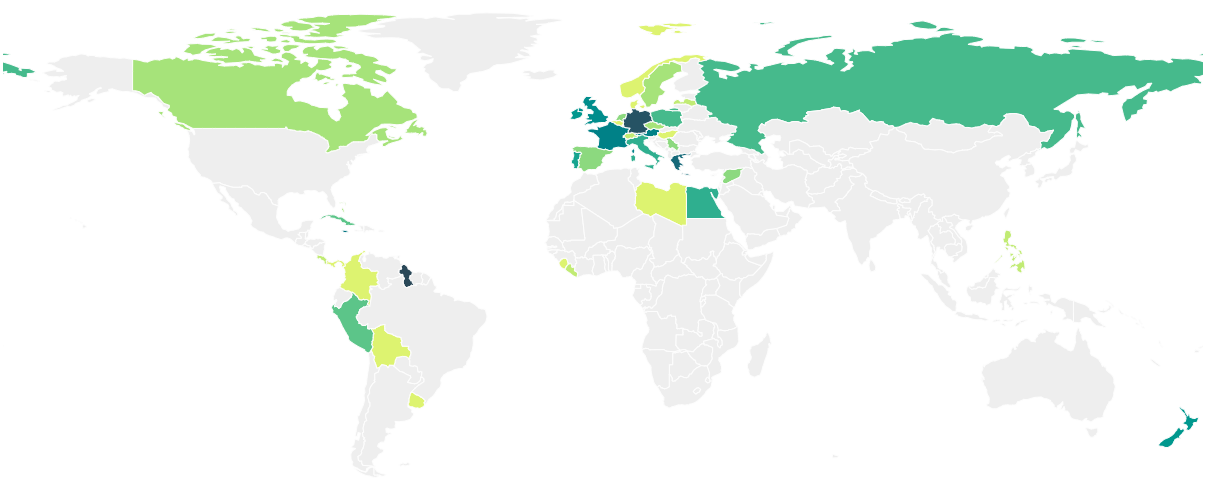
There are a couple of surprises that seem legitimate rather than spurious. There are 6 places in the US named Havana (i.e. the capital of Cuba), and one place named Tripoli (the capital of Libya). Given the history of the relations between the USA and those countries, I find that surprising.
Because of the concentration of results in Europe, there’s a zoomed in version to show the detail of Europe. Here you can see that the winners (excluding Georgetown, as mentioned above) are Berlin (16), Athens (14), Paris (12) and London (11).

Looking the other way, from the USA to other countries, you can see there’s a general but not completely clear trend that the closer you get to the North East, the more places there are that copy other countries’ capitals. There are lots of potential complication factors here, like population density, ethnic make-up of people who have lived there at various times etc.

Please note that, while I’ve put some care into checking my working, there are bound to be mistakes in this. I think that false negatives (I miss matches that I should have found) are more likely than false positives (I match two things that are different).
Summary
I hope that this shows you a couple of things. First, the information itself about US place names and other countries’ capitals. Second, how you can produce interesting and nice to look at visualisations without expensive or hard-to-learn tools, using information that’s easy to find on the internet.

Do you think you could make it work with LibreOffice Calc ir Google Sheets instead of Excel?
Of course some of the text bashing could be done with curl plus sed/nawk or perl.
LikeLike
There are two bits to the spreadsheet part. First, it looks like LibreOffice Calc has its own VLOOKUP (https://elearn.ellak.gr/mod/page/view.php?id=3016) as does Google Sheets (https://support.google.com/docs/answer/3093318?hl=en-GB). The second is less clear-cut – I don’t know if they could cope with the size of spreadsheet. It’s not the biggest in the world, but also not trivial.
Yes, some of the text bashing could have been done via command line tool of your choice. I guess it’s what feels closest to hand, and for me in this case it was Notepad++.
LikeLike
If you wanted to takwe this exerciose firther, there atre two ways you could expand the criteria:
1) Include Canada. (Because London, Ontario, for one.)
2) Include cities a bit further down the population order. (i.e. Birmingham, Al.; New York, NY; or [combining with 1)] Calgary, Alberta – the original Calgary in a tiny settlement on is Isle of Mull.)
I spent my student days in the Tyneside city of Newcastle upon Tyne, and it always used to amuse me to see buses with destinations of Washington or new York!
(and mentioning Newcastle makes me think that after you dealt with Canada, you might as well do Australia [Melbourne, Derbyshire for one] and/or New Zealand [Wellington, Shropshire or Christchurch]. You should probably draw the line at the Falkland islands [Stanley, also Derbyshire] or people might begin to think you were beginning to get obsessive…:-) ).
LikeLike