This article is the first in a series:
- How far away is the most remote part of the UK?
- How far away is the closest bit of the EU?
- Which bits of the EU are the closest?
I like visualisations, particularly map-based ones. Done well, it’s as if they give you superpowers or a microscope or telescope – you can see something that normally is hidden from you. They help you to understand something, and in business that often means they help you to make a decision. Below is a visualisation that I’ve made – I’ll explain what it represents and give a summary of how I did it, plus talk about some general stuff to do with visualisation.
- Contains OS data © Crown copyright and database right 2020
- Contains Royal Mail data © Royal Mail copyright and database right 2020
- Source: Office for National Statistics licensed under the Open Government Licence v.3.0
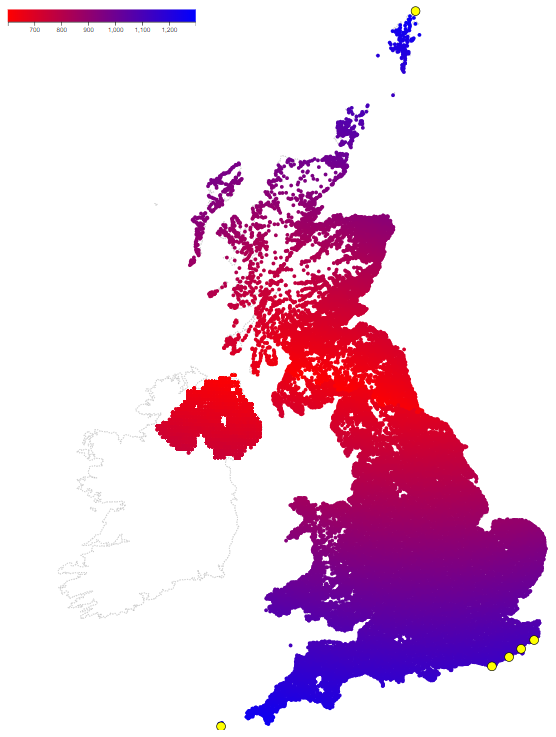
What the map shows
The visualisation tries to answer this question for each part of the UK: How far away from here is the most distant part of the UK? I’ve defined part of the UK to mean region covered by a UK postcode. The colour on the map represents the distance in km to the most distant part of the UK from here.
For each postcode, I found which postcode was the most distant and how far away it was. I looked at which postcodes were the most distant ones, and if I ignored differences in just the last character of the postcode, I noticed that there are only 6 postcodes that are the most distant postcodes from somewhere else. These are the yellow circles on the map.
The white regions are, I think, since each postcode region is encoded by a single co-ordinate, which in turn is displayed as a dot. When the postcode region is large, for instance due to it being a rural area with few people living there, the single dot doesn’t cover the whole region. When the regions are smaller, such as in the middle of cities, the dots pack closely enough together for there to be no visible gaps. If I had found data that encoded each postcode as all the co-ordinates that specify its border, then I could have done a proper choropleth map – big regions would have had a big irregular-shaped blob that filled the region, rather than the same size of blob as the smallest region.
Note that the distance is as the crow flies, and doesn’t worry about important practical details such as the road network, or the need to use ferries or planes to get between places. If I had to worry about that, then I would have needed much more data and probably ended up with something that looked like Mapumental.
My reaction to the map
My first reaction was how far north the centre was – a line going from roughly Hartlepool to Gretna Green, i.e. very roughly the England / Scotland border. The Shetlands being so far north is probably the key. I think it’s no coincidence that most UK maps have the Shetlands displayed in a box that relocates them further south e.g. off the coast of Lossiemouth.
That made me realise that this is a symptom of conflating England and the UK. I had, without realising, internalised the idea that middle of the country meant the Midlands i.e. the region around Birmingham. It reminded me that the Romans called the sea between Spain, Algeria, Israel etc. the Mediterranean – in the middle of the Earth. The position of the middle depends on which region you’re thinking about.
I was also surprised by the location of the yellow blobs. The Shetlands and the Scilly Isles were as expected because they’re the furthest north and south. However, I thought that there would be one on the west border of Northern Ireland as it’s the furthest west. In the context of the whole UK, Northern Ireland is roughly in the middle north / south, and so I imagine that the overall north / south orientation of the UK means there will always be somewhere more distant than Northern Ireland by going north or south in Great Britain.
Similarly, there are no blobs off the east coast of Norfolk – the furthest east (I think) but closer to the middle north / south than e.g. Kent. Four blobs along the Kent coast was also a surprise – I guess these are the furthest away for different parts of the Hebrides.
How I made the map
I started doing this in the simplest way I could – after reading in the data for each postcode into a list in memory, the code compared each postcode with each other postcode. I didn’t want to waste time doing fancy optimisations without knowing that they would be worth it.
It’s no surprise that an optimisation was worth it – my laptop took so long to complete even 0.01% of the work that I realised it would take far too long to finish. The complexity of the problem is O(n^2), so when N=1.7m the time taken is enormous and chopping N down will have a disproportionately big benefit.
I thought I could speed things up by considering postcode regions, i.e. the region of the country where the postcode starts with e.g. WC or SK. This is because there’s no point in comparing e.g. all the points in Cornwall against all the points in Devon, when there’s Norfolk and the north of Scotland much further away from Cornwall. If I could work out which regions were far from which other regions, I could limit the detailed comparison of individual points to a much smaller set of pairs of points.
I wasted some time thinking about Djikstra’s algorithm to see if I could work out which postcode regions were the furthest away from each other. This involved looking at which regions were next to which other regions, and trying to compute the number of regions you have to get through to travel between any pair of regions. It’s a nice algorithm, but not the best fit for this problem.
Once I realised that this wasn’t worth the time, I thought of a simpler approach. I picked the first postcode in the list for a given region to stand for the region as a whole. Instead of 1.7m points, there were now fewer than 200. I then did the simple O(N^2) comparison to work out how far each region was from each other region.
Because each region was represented by one point within the region that was chosen effectively at random, I didn’t want to rely on this comparison to tell me the one furthest away region. Instead I picked the 5 regions that were furthest away from each region. This didn’t shave off as much time as going with the 1 furthest away region, but it was still a big enough improvement that I was happy to wait for the code to finish. There’s still a risk that I missed the region that contained the point that was truly the furthest away, but I’m happy that this risk is small enough to live with, particularly given how big the regions are at the edges of the country. This was a time / risk to accuracy trade-off, and I’m comfortable with the approach I took.
Once I’d crunched the data I used d3 to turn it into a picture, including its topojson extension. This article has a screenshot of the output rather than the code and data because there are so many points that it takes a while to draw. I briefly changed things to sample the output rather than use every point, and while this reduced the rendering time it stopped the lovely colour gradient effect. If you’re interested in making maps using d3, I recommend a map making tutorial series from Mr d3 himself.
Important implementation details because this is a map
On top of the normal hassles do with data processing and visualisation, there are extra hassles because this is geographic data that I’m displaying as a map. It comes down to what you mean by a place’s location, and how this information is encoded.
If you want to be accurate about a place’s location anywhere in the world, you can give the location in terms of longitude and latitude co-ordinates. These cope with the fact that the Earth is roundish rather than flat. The mapping software (d3 + topojson) I used also needed points to be in longitude / latitude, as it’s designed to work on data about anywhere in the world.
The problem with longitude and latitude is that it’s hard to calculate distances between two points. It’s much easier if you can pretend that the Earth is flat, which is often a good enough approximation for small bits of the world, e.g. the UK. The process of converting locations on the globe into locations on an imaginary flat Earth is called projection, and there are many ways to do this. This is the reason why a world map looks different depending on whether e.g. the Mercator or Peters projection is used.
The Ordnance Survey grid reference is a set of co-ordinates on an imaginary flat Earth, just for the UK. These give the distance north and east from a point to the south west of the UK. To calculate the distance between two points, you can just do pythagoras on the east/west and north/south distances between the points.
So, for each point (post code) I need the longitude / latitude co-ordinates so that I can locate that point on the output map, and also the OS grid reference so that I can do calculations that say what colour that point’s blob should be on the map.
This is the unavoidable complexity given the problem I’m trying to solve. Because of the tool I chose to use, there’s a small bit of further complexity. Topojson is a special-purpose JSON file format for topological (map-based) data. It tries to make data files small in a couple of ways:
Bits of borders and other lines are things in their own right. If you’re defining a map with two countries that share a border, the details of the border can be defined once, and then each country can include the shared part in their overall border.
A transformation is defined for the file, which multiplies the values in each co-ordinate by the same amount, and adds another amount to each co-ordinate. The effect of this is that co-ordinates change from e.g. [57.149606,-2.096916] to [7498,6618]
General approach to visualisations
As I have said before, with visualisations it’s good to start with the end in mind. Once you know the end, how do you get there. In theory, the process has three steps:
- Get the data (e.g. the locations of postcodes, which I got from the ONS)
- Process it so it’s ready for visualisation (calculate the furthest postcode from each postcode)
- Turn the processed data into a picture (the coloured map with blobs on).
This suggests a simple linear process. In my experience, this is true as often as the following is the correct simple linear process for becoming a superhero:
- Get cape
- Wear cape
- Fly
Instead of a simple 1 ⇒ 2 ⇒ 3, there can be many attempts at each step until it works or even backwards steps. Problems with the processing mean you get different data, the visualisation turning out wrong means you change the processing or even get different data. Don’t worry – this is normal (at least for me).
You might notice some limitations to the map. The ones I know about are:
- There’s no title;
- The scale’s odd and small;
- The Scilly Isles blob is chopped off at the bottom.
I imagine I could fix these eventually, but to be honest this project took me much more time than I’d hoped, so I just wanted to get the thing out as it is and then move onto something else. It’s good enough for me, even though it’s not perfect.
Speaking of time, spending time to get good quality data can save you more time later. Not only will the results be more likely to be accurate, the processing of them might be simpler. The data might have fewer rejects that need dealing with, or might be in a more suitable form and so need less processing. For instance, instead of having (postcode, longitude/latitude) and (postcode, grid reference) as two separate files that would need joining, it’s simpler to have it already joined in one file.
It’s possible to test the data processing if the visualisation is worth the trouble. Even after automated testing, it’s worth doing simple checks of the visualisation. In the case of the map above, I looked at another map of the UK that already had a scale, and physically measured the difference between the Shetlands and the Scilly Isles, and then compared that distance to the furthest distance on my map.
Summary
Visualisations done well can help you to see things that would otherwise be hard to see, and so help you to know more about the world. If you know how to code, I suggest you find a question you think that a visualisation might answer and have a go. It can be frustrating and hard work, but also rewarding.
UPDATE 28th Feb 2020: In the light of Robert Day’s comment, I’ve changed every “remote” to “distant” because I wanted my meaning and intention to be clearer.

An interesting exercise, though I have to make two observations:
1) It certainly doesn’t take geography into account, though the white areas are something of an indicator. But the Lleyn Peninsula (north-west Wales) is shown as less dark blue than areas to the south which are far less “remote” in any real sense.
2) And it is at complete variance with population density. The least remote areas on your map are in a band from the West Highlands of Scotland down to Northumberland and County Durham, and whilst it includes Glasgow and Middlesborough, it also has a lot of places which would look pretty remote if you were boots on the ground. For instance, it includes Kintyre, which if you go there is a very long way rom anywhere else. And four of your “most remote” places are on the south coast of England, which if you go there are about as unremote as anywhere!
I think you’ve spotted the problem when considering the nature of postcode areas. As I once worked on a project which involved using postcodes for routing maintenance workers to jobs, they are a compromise specifically designed to help posties to organise their work by optimising the routing of mail. But for that purpose, they have to be overlaid with another distribution, that of the availability of postal delivery staff; and that has to take into account the fact that postal workers are whole integers; you can’t represent the staff required to deliver a letter to the remotest part of the British Isles by 0.01 of a postie! Certainly, the people who designed the postcode system – one of whom I worked with – knew that the geographical coverage was only part of the problem.
So if you were going to continue this line of enquiry, I think you’d need to think of another parameter to overlay this data with for “remoteness”, possibly looking for a data source that takes into account things like Central Place Theory…
LikeLike
Thanks for your comment. I think the problem comes from my use of the word remote. Distant would probably be more accurate.
For this map I’m interested only in physical separation of places, not cultural or social distance, population density etc. Post codes were just a handy way of filling the inside of the UK with about the right number of samples. In this map I’m not interested in how the post system is organised.
I hope to do some more maps that build on this one, and I’ll be more careful in how I describe things if I ever write those up.
LikeLiked by 1 person
It’s still worth your doing the exercise because the time might come when you have to participate in a project involving this sort of study, or test a system designed to look at distribution, manage fuel costs or schedule calls.
LikeLike
I agree it would be an interesting project, but unfortunately I have far too many ideas for interesting projects for this to get to the top of the list any time soon. 🙂
LikeLiked by 1 person
Oh Bob,
I now see I’ve found another Robert to follow from your comments. At this rate I’ll need to formally pencil in time to read blogs. Keep up the interesting work.
LikeLiked by 1 person