In this article I will give a high level overview of building a CI / CD pipeline using Jenkins and Octopus. There are alternative tools, and also other ways to use Jenkins and Octopus – please treat this as just some suggestions. I won’t try to answer all questions you might have about Jenkins or Octopus – I hope after reading this article you will be better able to research the details elsewhere online.
What are we trying to achieve?
We are trying to build a production line. It will take as raw materials source code, config files etc. from a source control management system, e.g. a repository in GitHub. All being well, it will produce a deployed and ready to run version of the executable on a remote machine e.g. a test server. The production line must stop if there is a problem, rather than trying to continue.
We want the process that turns source code into a deployed system to be as painless as possible. At the worst, we want the user to say GO only once e.g. clicking on one button once. At best, it should happen automatically, e.g. every N minutes or whenever some existing kind of event happens e.g. when a GitHub pull request is approved.
The minimum we’re trying to do is all these steps:
- Read the source from GitHub;
- Build the executable;
- Package the code ready for deployment;
- Deploy to one server.
It might not be obvious why building and packaging are separate. Building or compiling will produce many DLLs etc. in bin directories. Packaging groups these together into e.g. nupkg or zip files (or even, I think, Docker images) that are easier to move around as there are fewer of them, that often better correspond to higher-level business-y concepts such as payment.
Other things that might make the production line more complicated include:
- Running unit tests (e.g. between build and package);
- Running integration or system tests (after deployment);
- Announcing when the process starts and ends (success or failure) to people e.g. via Slack;
- Updating the state of (human) work management systems, so that it keeps aware of where the code corresponding to each human task has been deployed. E.g. tell Jira that the code for story DEV-123 is now on the test server.
- Deploying to more than one machine.
Deploying to more than one machine can be either automatic as part of a larger end-to-end process, or only when explicitly asked for after e.g. some non-automated testing. Automatic deployment to more than one machine might be like this:
- Build, unit test, package
- Deploy to server A ready for automated tests
- Run automated tests against code installed on server A
- Deploy to server B ready for manual test.
This assumes that the contents of server A (and particularly e.g. its database) can be treated as disposable. Server A’s database can be wiped to a known state before or after each run of the automated tests. Server B’s database is more likely to contain test data or test code that’s valuable enough to want to keep over time.
What are Jenkins and Octopus?
They are both configurable workflow engines, but with differences that mean that you would probably want to divide jobs up between them in fairly predictable ways, such that they both play to their respective strengths, as this is likely to be easiest for you.
- Jenkins has lots of plug-ins, and so is good at talking to random other bits of code.
- Jenkins is flexible, e.g. you can tell it what to do via a config file. The config file can include entries along the lines of run this arbitrary command line thing e.g. a batch file. This makes it a good candidate for building code, running unit tests etc.
- Octopus is good at being aware of other machines, knowing their credentials, knowing what roles those machines play (e.g. database server vs. web server, test vs. staging vs. production), and what releases of code have or have not been successfully deployed to each.
- Octopus is good at knowing how configuration, e.g. database connection strings, should vary by machine.
Octopus can run arbitrary code after deploying, but it is e.g. a PowerShell script and doesn’t draw on any integrations or plug-ins offered by the underlying platform so you’re on your own.
Octopus works on a hub and spoke model – there is a central server that receives code to deploy, where configuration lives etc, and then there’s a spoke (or tentacle in Octopus-speak) on each server you want to deploy to.
You can deploy Jenkins over many machines to e.g. do things in parallel more quickly – in this article I’m assuming it’s on a single machine, doing a single stream of work.
Dividing up jobs between Jenkins and Octopus
The diagram below shows one way of dividing up the jobs between Jenkins and Octopus. In the next sections I’ll start with a simple way of implementing this, and then build on it to do more useful things.
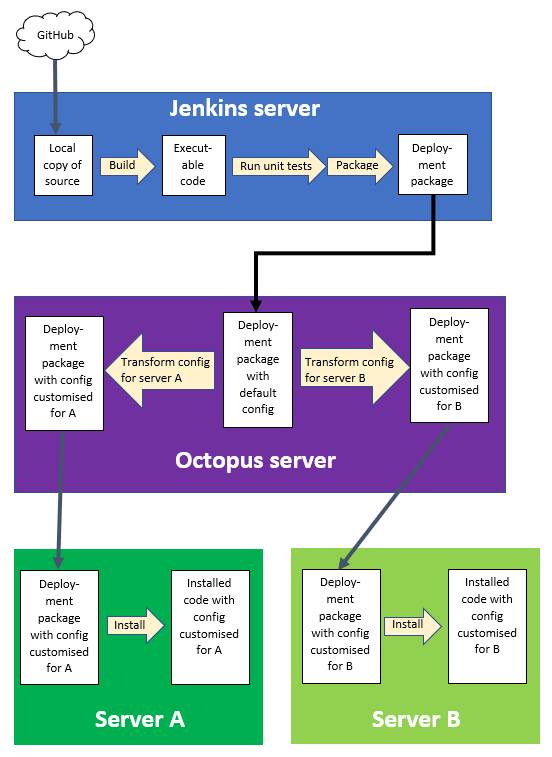 Jenkins server -> Octopus server -> two servers to deploy on” width=”552″ height=”757″>
Jenkins server -> Octopus server -> two servers to deploy on” width=”552″ height=”757″>
Simple approach
A key detail missed out from the previous diagram is control, i.e. what is in charge of what. The simplest approach is for Jenkins and Octopus to each be in charge of their own stuff.
What this means is that once the deployment packages are ready in Jenkins-land, Jenkins throws them over the wall for Octopus to deal with. Up to and including this point, Jenkins is doing the work and Jenkins is in charge. After this point, Octopus is doing the work and Octopus is in charge.
A little bit of practical detail – “Jenkins throws them over the wall” means that Jenkins will send the packaged code to the Octopus server over HTTP, using a secret token from Octopus that means Octopus will trust Jenkins as a sender of code. Octopus will react to the HTTP message by copying the code it receives to a directory that is configured to act as the inbox for Octopus.
Octopus will poll its inbox and spring into life as soon as it detects new stuff. It will then transform the configuration of the packaged code and deploy it via the relevant tentacle to the remote server. For more details, see my previous article on Octopus.
More sophisticated approach
In the previous approach, Jenkins stops its involvement after it has copied the packaged up code to Octopus’ input directory.
We can change this, by separating is in charge of from does the work slightly. Octopus will remain as the thing that transforms configuration and deploys code, but now won’t automatically spring to life when it receives new code. Instead, it will do things only as directed by Jenkins.
The export of packaged code from Jenkins to Octopus in the previous section is via an Octopus command line tool. There are other similar tools that let you control it over HTTP. These command line tools can be used by Jenkins, so that after it has packaged up the code and sent it to Octopus, it can then tell Octopus to deploy the code to a remote server.
The advantage of this is that there is a single view of the status of the end-to-end process. It’s easier to see what work has finished and what’s still to do – it’s all on one web page (the Jenkins page that displays a build’s progress). It’s easier to export this status elsewhere, e.g. to Slack or Jira, as the status is now exported from only one place.
It also makes it easier to add in automated integration and system tests and possibly deploying to multiple machines as part of this. Running the tests is likely to be done more easily from Jenkins than from Octopus as it’s likely to already be running the unit tests. So, the Jenkins pipeline could become:
- Get latest source from GitHub
- Build it
- Run unit tests
- Package for deployment
- Use Octopus CLI tool X to send the packages to the Octopus server
- Use Octopus CLI tool Y to tell Octopus to deploy the packaged code to the automated system test server
- Run automated system tests
- Use Octopus CLI tool Y again to tell Octopus to deploy the packaged code to the manual system test server
Shifting complexity for a many-part deployment
Imagine that the code you’re deploying is in many parts, e.g. a website divided up into separate applications. These are built separately but you want to deploy them together to avoid the risk of inconsistencies of code or database schema. (Yes, micro-services and other things would make things nicer, but I’m assuming you have this problem.)
To use Octopus you will need to define how to deploy each part as a separate Octopus project, which will say which bit of packaged code it’s built from, which type[s] of machine to deploy it to, what the installation directory is etc. However, you can also define an umbrella Octopus project that, instead of specifying any of the things that make up a normal project, instead specifies one or more child projects to deploy.
In the list above, you need to repeat step 5 for each separately packaged bit of code. If you don’t use an umbrella project, you also need to repeat step 6 and step 8 for each package. However, if you use an umbrella project, while you still need to repeat step 5, you do step 6 and 8 only once each.
This shifts complexity relating to the deployment of code from Jenkins to Octopus, where it belongs, while keeping the view of end-to-end progress in one place – Jenkins.
Summary
Jenkins and Octopus form a good combination for a CI/CD pipeline. Jenkins is flexible, and Octopus specialises in handling deployment and the steps immediately before it e.g. tailoring configuration for specification deployment destinations. By keeping Jenkins in control, and delegating to Octopus where necessary, you keep a single source of truth for the status of some code’s progress along the pipeline from end to end. This makes reporting and exporting that status simpler.
