This is the first article in a short series on fuzzy matching:
- Introduction
- Example algorithms
- Testing and context
In this article I’ll describe how fuzzy matching is different from non-fuzzy or conventional matching, why you might want to use it, and some of what makes it hard.
Conventional matching
In conventional matching, when you compare two things to see if they’re the same you can get two possible answers: yes and no. It’s important to separate out the binary yes/no answers from other aspects of the comparison, as more complex comparisons can still be conventional rather than fuzzy.
At the simplest end of things, there’s a matching based on being exactly the same as something. In one hand I have a text string with the value “Tuesday”, and in the other I have a mystery text string I’m comparing to the first one. If the mystery string is also “Tuesday”, then the answer is yes, otherwise it’s no. There’s a wrinkle here – does e.g. “tuesday” also match i.e. is it a case-sensitive or case-insensitive match? Both options can be valid as it depends on the context.
Moving up the complexity scale, there are cases where some variation is allowed. This could something like a message being valid if it contains the following in this order:
- A header
- One or more lines of body
- A footer
It’s possible to have a yes/no answer to this comparison, even though the number of body lines could be any integer greater than zero. The comparison could be implemented using a finite state machine, where a match is defined by the state machine being in an accepting state when the input messages end. I will describe how finite state machines can be extended to allow fuzzy matching in the article on example fuzzy matching algorithms.
Fuzzy matching
The key difference in fuzzy matching is that there’s now a new possible answer: maybe. (You might prefer to use a synonym to maybe, such as a bit.) Yes and no might still be valid, but the key thing is that there are now shades of grey, and some shades are likely to better than others.
It might be that maybe / a bit is a useful answer, but often it needs to be resolved eventually into yes or no. I.e. there might be a web of calculations hidden from the user that accept and produce variations on maybe, but eventually a user needs just yes or no.
There are two sources of potential difficulty:
- How do you calculate a useful value for maybe?
- Where do you draw the line in the range of maybe-related values, to separate good enough from not good enough?
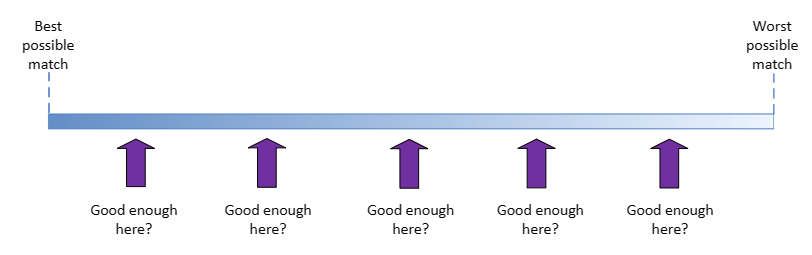
In practice, yes/no/maybe is represented by a score e.g. in the range 0-1 or 0-100, where 0 means no, 1 or 100 means yes, and maybe is all the values in between. There needs to be some algorithm for producing a score in the range 0-1 to show how good the match is. Even though it might be possible to defer doing so for a while, eventually a decision usually needs to be made about which score is the dividing line between yes and no.
What fuzzy matching is trying to do is to cope with variation in one of its inputs. It gives tools to allow you to say that variation up to a certain point is OK, but beyond that it’s not.
More complicated fuzzy matching
Fuzzy matching problems are often more complicated than is suggested by the diagram in the previous section, in at least two ways:
- There are two or more properties that need fuzziness at once, probably using different patterns for the shades of grey;
- There are two or more things to be matched against, e.g. checking some incoming speech against a dictionary of tens of thousands of words.
One way to picture it is via a diagram like the one below:
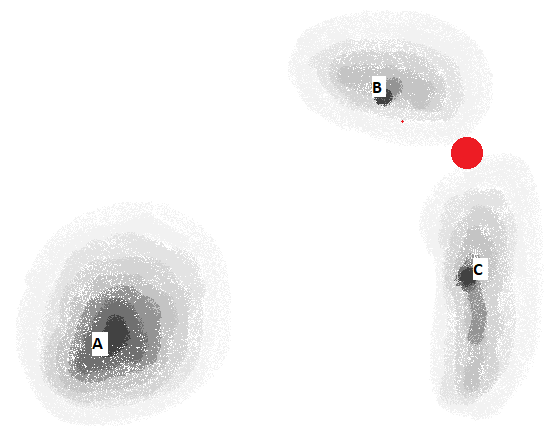
In this example there are two properties of the things being compared, which correspond to the x and y co-ordinates of the chart. The properties could be something like height and weight, or duration and frequency. Note that in some applications there are many more than two properties* being fuzzy matched at a time.
In the diagram above, the different expected outcomes are marked by text in capital letters. The quality of the match for a given outcome is shown by the darkness of the shading around its label – the darker the better.
The point labelled with the red circle shows a problem with fuzzy matching when there is more than one possible expected outcome. I.e. instead of a single yes/no/maybe answer, there is a separate yes/no/maybe answer for each possible outcome. The red circle is something that’s ambiguous – it’s a poor but non-zero match for two possible outcomes.
This is not necessarily a flaw of the fuzzy matching algorithm. People mishear one thing as another, even when they are listening to their mother tongue being spoken by someone they know well. For instance “up at 8 o’clock” can sound like “a potato clock” in many dialects of English. In other words, a series of sounds is a match for both meanings.
It might be possible to use context to work out which of the two or more possible matches is the better one, but not always.
* For instance, in speech recognition the input could be a series of audio samples. Instead of each sample being a single number representing the total volume, it could be an array of e.g. 20 numbers, with each number representing the volume over a different range of frequencies. If you look at some spectrograms, you could imagine overlaying a grid on the spectrogram – the vertical lines of the grid divide the audio up into samples, and the horizontal lines divide each sample up into a series of frequency buckets.
For each bucket and sample, the value is linked to the total or average intensity or volume in that cell of the grid. This way a high frequency sound can be distinguished from a low frequency sound, even if their overall volume is the same. Fuzzy matching could happen separately against each value for a sample, i.e. it would be a 20 dimensional space rather than a 2 dimensional space as in the diagram above.
Example applications
Some examples of when you might want to use fuzzy matching are speech recognition and coping with text that has typos in it.
In speech recognition you have some input audio that you are trying to match against a set of models that represent the words that the system knows. The simplest approach would be to see if the input speech exactly matched some previously recorded speech, but that wouldn’t cope with expected variability.
The variability could be between different genders, ages and dialects of different speakers, plus variation within one speaker’s speech that encodes how tired they are, their emotional state etc. Fuzzy matching allows the system to have a series of models, and then score the input speech against each model, and pick the model that gives the best score.
If the system accepts text from a user, the text could have typos or other errors in it. One approach to this (other than rejecting the errors) is to list all the allowed versions with errors, and link them to an error-free version. The system would then do a conventional match against one of the variants (or none at all).
An alternative is to store only the correct versions of things, but match input text against the stored text via fuzzy matching. This would allow small errors (where small needs to be defined) to still be accepted.
Setting boundaries
In the next article I will go into one of the two sources of potential difficulty I mentioned earlier – how do you come up with a useful score for the match?
This leaves the other difficulty – how do you know where to draw the line between good enough and not good enough? Unfortunately, the answer is often some version of: it depends.
In the simplest case, the system is matching an input against one known thing. There are therefore four cases to this match, as shown in the table below.
| Result is correct | Result is incorrect | |
| Input doesn’t match | Input correctly doesn’t match (true negative) | Input incorrectly doesn’t match (false negative) |
| Input matches | Input correctly matches (true positive) | Input incorrectly matches (false positive) |
The problem is it’s hard to get just the outcomes in the result is correct column. If the match is restrictive, you’re increasing the chances of getting the top row – a mix of true and false negatives. If the match is permissive, you’re increasing the chances of getting the bottom row – a mix of true and false positives.
It depends on the context what the relative value of the four cells is – is it better to err on the side of excluding things when you shouldn’t, to make sure all the positives are valid, or is it better to err on the side of including things when you shouldn’t, to make sure you don’t miss any matches? One approach (which may or may not be valid for a given context) is to adjust parameters until you get an equal rate of false negatives and false positives.
Things get even more complicated when there are several possible matches, e.g. matching input speech against a dictionary of words. Here, not only could an error be that there is no match, there’s another class of error where a match is found against the wrong thing. Like with the previous case, it depends on the context where the lines should be drawn.
How do you decide between conventional and fuzzy matching?
The simple answer is that you should probably use conventional matching if it gives good enough results. Fuzzy matching often takes longer than conventional matching, for reasons I hope will become clearer when I go into some examples in the next article. Also, conventional matching is usually easier to understand, so debugging and doing customer support is likely to be simpler if code uses conventional matching rather than fuzzy matching.
