I was driving recently, and realised that I was near a road that appeared to have a large gap. By that I mean: road A joins road B and stops, but some distance further along B there’s a bit more road A. It’s as if A has been chopped into two by B, and the two bits slid apart along B. I could think of another road like that, and wondered how many more there were in the UK. It turns out there’s quite a few. Time for some more data munging leading to some graphs and a map.
Data
The data I found was the Ordnance Survey Open Roads, which gives data for roads in Great Britain (sorry, no Northern Ireland data). It’s for motorways down to minor roads, in loads of detail. Each junction or time a road changes its name is called a node, and the data describes every node, and every bit of road between every node. The version I downloaded was the XML version, rather than a more exotic format such as an ESRI Shapefile or GeoPackage. This is 52 files (one for every major grid square on an OS map), and just under 7 GB in total.
Each node has a unique id, as does each bit of road (called a road link). Each node has its location and a few other bits of data. Each road link says which two nodes it goes between, whether its fictitious or not(!), what kind of road it is (A road, motorway etc.) and 1 or 2 names. A road link always has a road classification number, which might be A1307, and it might also have a name e.g. Huntingdon Road.
Processing
I decided to limit things to just A roads and motorways. Even so, there would be a lot of data, and roads such as the A1 will span many files. So the code needed to process each file only once, building up data in memory as it went.
Each time a road link was read in, it was checked against the data already read in. If the road was a new one, then the road was created with this road link as its only data. If the road was one for which there was already data, the new road link’s node ids (that described its two ends) were checked against the node ids already known for that road. If there were any matches for it, the new road link would be added to that data. If the new road link’s node ids weren’t already known, a new set of node ids was started for the road (so that there were two or more sets for the road).
It’s a bit like a game of dominoes – can a new road link be added to the end of an existing road link, because the numbers on the end match? If yes, the arrangement of dominoes is extended. If no, then an extra arrangement is started (with just one domino) alongside the existing dominoes for the road. It’s a little more complicated than that – there could be two existing separate sets of road links for a road (i.e. that don’t join up) and a new road link forms a bridge between the two sets. This means the two sets need to be merged into one.
At the end of processing, how many sets of road links are there per road? If there are two or more, then there are gaps in the road.
Messy data, or the trouble with the Dundee ring road
I ran into a problem that seems to happen with every data processing project I do, which is messy data. An example of this is the A991, which is a ring road around Dundee (I just happened to pick on it at random when debugging, as it was a small example of things being wrong).
To start off, I added some extra debug statements to my code, in the hope that this would show me what was going wrong. Unfortunately this didn’t help much, as it was like trying to understand The Matrix:

I thought that the debug data might actually be helpful enough, just presented poorly. So with only a little bit of massaging I turned it into an input file for GraphViz, so it could draw out what road link connected to what. This was a little bit more helpful:

The A991 looks like this on a map (in this case, OpenStreetMap) – it’s the pale orange road.

I could match the road names (West Marketgait etc.) between the graph and the map, and the junction near Dundee railway station at the bottom of the map was the problem. In the data, there is no joining up of the A991 there. On OpenStreetMap you can ask it for information about each bit of road, so you can see that South Union Street (highlighted in red/orange) is part of the A991:

This way I could tell that OpenStreetMap also had a gap in the roads tagged as belonging to the A991, although its gap didn’t match up exactly with the gap in the OS data. The bit of the Riverside Esplanade highlighted in red / orange isn’t tagged with A991 (this is from OpenStreetMap), even though the OS data described it as part of the A991.

I checked the Ordnance Survey’s own online map to see if that would clear things up, and it didn’t. There’s less information and less helpful colouring than in OpenStreetMap:

Google Maps is different again! (I’ll let you imagine that / look it up for yourself.)
I decided to keep my life simple and just ignore any gaps less than a certain size. The threshold for ignoring gaps is arbitrary, and I wanted to err on the side of caution. That is I’d prefer to miss gaps that were there than treating noise in the data as a gap when it wasn’t one in real life. So I decided to go for a figure of 500m, as the location information was in metres (OS Eastings and Northings), and 500m is the biggest value that would round down to 0 if you round to the nearest kilometre. I know that’s still quite arbitrary, but I had to draw the line somewhere.
I also wanted to make sure that A roads becoming motorways didn’t introduce a gap, as in real life that’s the same road. For instance, the A1 becomes the A1(M) in places. If a road ended in “(M)” I ignored this, to avoid brief spells as a motorway introducing spurious gaps.
To err is human
I don’t always go into all the messy details, wrong turns etc. when I blog, because it would take too much time to write, and too much time to read (and so you’d probably lose interest). However, I’ve recently enjoyed watching videos by Tom Stanton and Stuff Made Here, and part of what makes them enjoyable is that you see the failure and frustration and disappointments, so that success seems properly earned.
It’s worth remembering that this is in the context of physical projects – planes flying or crashing, robots working or not etc. – which is a much more interesting kind of failure than someone writing about debugging software. I don’t want to give the false impression that everything goes swimmingly with this blog, but nor do I want to bore you. So, please imagine these posts are the tip of an iceberg, where the iceberg is mostly frustration and “Why isn’t it working?!”
Calculating the size of gaps
As I mentioned above, each road with gaps in had two or more separate sets of road links. I went for a brute force approach, and for a pair of sets A and B, calculate the distance between each node in set A and each node in B. I then took the minimum distance for the pair as the distance between sets A and B. If a road had more than two sets, then it wasn’t obvious which set was closest to which other set, so I extended the brute force approach to try each set with each other set, and say that the distance between a given set and the rest of the road was the minimum distance between that set and all other sets for the road. With all these distances calculated, I then took the biggest distance across all sets for a road to represent the road as a whole.
Roads with different sizes of gaps
This chart shows the number of roads that had a maximum gap of a given size, grouping gap sizes into ranges:

Yes, there are roads that have gaps of over 300 km! Most gaps are less than 10 km.
How many sections per road
I wanted to know how common it was for a road to be split into 2 or more sections (where I ignore gaps of less than 500m). This table shows how common it is for a road to have a given number of sections.
| Number of sections | Number of roads with this number of sections |
| 6 | 1 |
| 5 | 2 |
| 4 | 9 |
| 3 | 35 |
| 2 | 160 |
| 1 | 119 |
This takes a little explaining, partly because this is an instance of counting fence posts vs. counting fence panels, and partly because of ignoring small gaps.
If a road has 1 gap, it will have 2 sections (in the posts / panels analogy, the gap is the fence panel and the sections are the fence posts). If a road has 2 gaps, it will have 3 sections etc.
However, imagine that the road has 2 gaps but 1 is below 500 m. It will have sections A, B and C. Imagine that the B – C gap is the one below 500 m. This means that only section A is separated from the rest of the road by a gap we’re counting. B and C are close enough to another section (the other one in the B / C pair) that their distance from the rest of the road will be below 500 m and we won’t count them. So a road that is ‘split’ will have only 1 section in the table above. Without this ignoring of small gaps, the smallest number of sections a split road could have is 2.
The maximum number of sections if you include gaps of any size is 16 (the A38). Ignoring gaps below 500 m, the roads with the most sections are:
| Number of sections | Roads |
| 6 | A361 |
| 5 | A6, A422 |
| 4 | A44, A417, A350, A272, A513, A489, A371, A63, A264 |
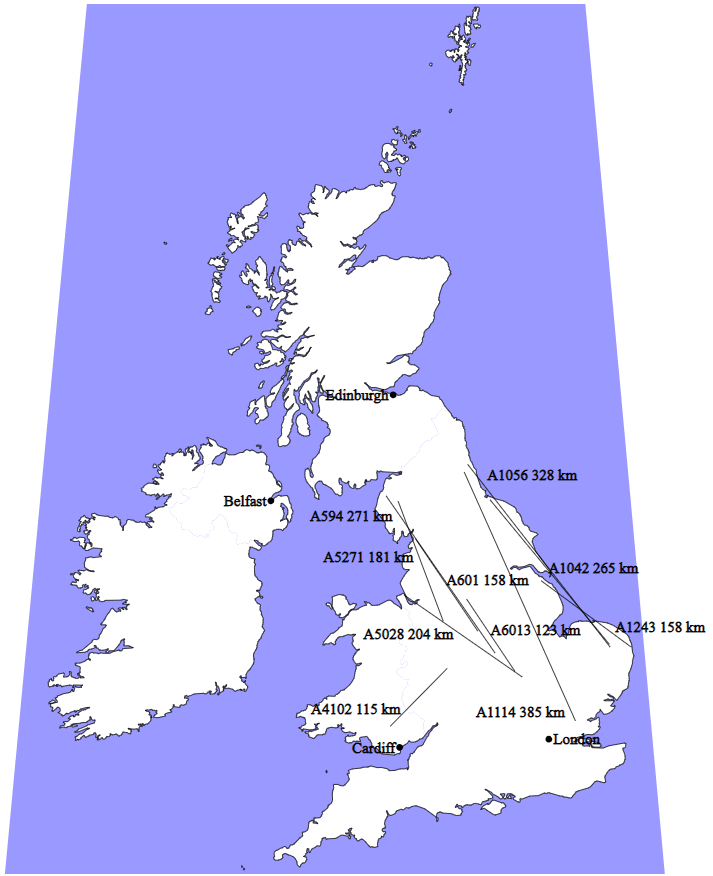
Biggest gaps
This map shows the ten roads with the biggest gaps. The line shows the gap in the road, i.e. where the road isn’t. There are bits of the road at each end of the line. Sorry about the labels being hard to read – I suggest that you type the road name into an online map to explore the details of the ends of each gap.
Summary
There’s no big point to this post – I was just curious, and followed that curiosity into some data. I don’t know why there are gaps as large as on the map. My guess is that they aren’t actually one road split into two. Instead, there are two unrelated roads that happen to re-use the road number.
UPDATE 7th December 2020: Added section on number of sections per road
