When a system needs to change from one version to the next, this can be disruptive and risky. One approach to reducing this disruption and risk is a via a blue/green approach. Changing from one version to the next is also known as migration, upgrading or updating. I will describe the blue/green approach using three examples – tariffs in UK domestic smart meters, the Swedish road network, and software.
UK domestic smart meters
SMETS2 is the current standard for UK domestic smart meters. It contains these requirements (and many others):
- Tariffs must be downloaded and stored in a customer’s meter, so that it can support the customer having an accurate and up to date idea of how much they’re paying for energy.
- When a customer changes tariff (either between two tariffs from the same supplier, or from one supplier’s tariff to another supplier’s tariff), the new tariff must take effect at midnight.
The problem is the communication network that supplies tariffs to meters is also the network that lets the meters phone home with meter readings. Sending the readings home is the majority case, and so the network is built mostly with that in mind. The reliability and throughput are kept low, which is good enough for meter readings and is cheaper than a more reliable and higher throughput network.
This makes it tricky to deliver a relatively large lump of data (the tariff) reliably just before midnight. The solution is to deliver the new tariff gradually and ahead of time, with an effective date in the future. If there’s a problem with the transmission, there’s enough time to try again.
However, while the new tariff is being installed the previous tariff still needs to be in force. That means there need to be two slots in the meter to hold tariffs. Also, two different suppliers need access to the meter (but only to their tariff’s slot), which means that security, credentials etc. are double what they would otherwise need to be.
Blue/green is a way to refer to this kind of approach. To change something (in this case, a smart meter tariff) with the minimum of disruption, you have two places to hold versions of the thing, referred to as blue and green slots (also known as the hot and cold slots). Only one version is active at a time, which allows the next version to be prepared in the spare place. When it’s ready, the system (in this case, the smart meter) can relatively quickly flip to the new version.
While blue/green can offer benefits, it does also have costs – in the case of smart meter tariffs, the meter and security infrastructure are more complex and hence more expensive. The balance of costs and benefits needs to be checked for each situation. Just because big, well-known and wealthy software company X does something doesn’t mean it’s necessarily the best approach for you, because for you the costs might outweigh the benefits.
Swedish roads

One of the many problems involved in this was the infrastructure that helps motorists use roads safely. This is things like road signs being on the wrong side of the road, road markings being in the wrong place etc.
To minimise disruption, the road signs and markings for the right-hand side of the road were installed ahead of time and immediately covered up. On change-over day (which had been widely advertised in advance), traffic was banned from the streets for a while, allowing workers to move the covers so that the right-hand version was revealed, and the left-hand version was covered.
There are a few reasons why I include this example. One is that change often includes a human element as well as a technical one. This is the sometimes boring stuff of emails and meetings, but without it even the best solution to the technical problems will be insufficient.
Another reason is to point out that while this approach reduces risk and disruption, it doesn’t necessarily eliminate them. You need to be prepared for failure even when you use something like a blue/green approach.
Software
Now we come to migrating software. In the simplest version of running software, you just have something to hold the software, e.g. a server, and route incoming traffic to it. However, to implement a blue/green approach, you need to make things a little more complicated.
First, you need a spare place to hold and run a version of the software. This means at least twice as much storage as before to hold the code. You also need something that lets you switch incoming traffic to one version of the code or the other. How you do this can vary, but they are all variations on indirection:
- At the simplest, you could have something like a UNIX symbolic link that points to the code in slot A or slot B. The link always stays in the same place with the same name (so that incoming traffic can find it) but what it points to changes.
- A more complicated version does the switching via software, sometimes called a load balancer. (The load balancer could do more than just flip between the two versions during a migration.) You might now be thinking that this is solving the problem of migrating software by introducing more software, so how does the new software (the load balancer) get migrated? This is a good question, and much of the time a good answer is that you try hard to avoid having to migrate the load balancer, by keeping it as simple as possible.

In some cases, such as an Azure AppService, the details can be hidden from you but something like this is happening behind the scenes.
There are a few ways in which software migration could be more advanced, i.e. complicated, than this.
Many instances behind one load balancer
In the previous section, we had one instance of the code running at a time (either one version or the next/previous one). When demand gets higher, you could have a load balancer sharing work out among many instances of the same code, so that they can deal with requests in parallel.
In this case, you can have a more gradual and less binary approach to migrations. If you have N instances of the code running in parallel, you don’t have to migrate all of them at once. You could add an instance of the new version and retire an instance of the old version (so you have 1 new instance and N-1 old instances). Once you have built up confidence in the new version, you can gradually repeat this process for the remaining instances, until you end up with just the new version running.
It’s worth limiting things to only one change at a time. I.e. you don’t start introducing version X+2 until all instances of version X have been replaced with version X+1. Otherwise, you will have three or more versions of the code running at once which can make debugging tricky.
Feature flags
Feature flags allow you to separate deployment (of code) from release (of behaviour). If done correctly this can reduce the risk associated with software releases and deployments even further than a simple blue/green approach.

The life cycle starts with version X of the software, that supports behaviour A. Behaviour A could be, for instance, a particular version of a form on a web page.
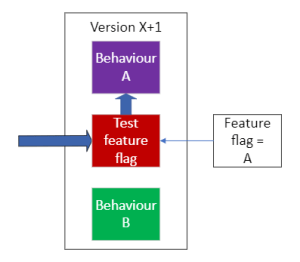
A new version (X+1) of the software is deployed. It supports behaviour A and behaviour B (e.g. two different versions of the web form) and chooses which behaviour to deliver via a variable or feature flag. When the version X+1 is deployed, the feature flag is set such that behaviour A is delivered. As far as the user is concerned, there has been no change – it appears that the software has continued unchanged, because its behaviour hasn’t changed.
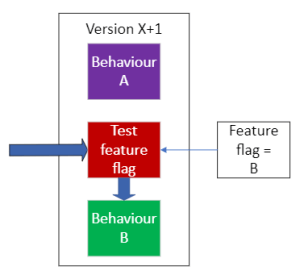
The feature flag is changed, which means that behaviour B is now delivered, from an unchanged version of the software (it’s still on version X+1). If things go poorly, the feature flag can be flipped back such that behaviour A is delivered again. This buys time for a new version to be created and deployed. This new version will support A and a hopefully fixed version of B.

Assuming the original version of B was correct, a new version (X+2) still needs to be created and deployed. The difference between versions X+1 and X+2 is that, while both can support behaviour B, version X+2 can do only this and doesn’t include a feature flag. We are now in a position where the life cycle can start again for the next feature.
It’s important that feature flags are removed when they’re no longer needed, to stop the software’s complexity from growing unnecessarily. Also, leaving old feature flags around means they might be reused accidentally, with potentially bad results.
Dependencies
So far, I have been glossing over an important detail, which is dependencies between parts of a system. For instance, version X+1 of the software needs a new column in a database table. This means that two (or more) migrations must happen. In this case: the new version of the software and changes to the database.
There is no perfect solution in all cases, but what you’re aiming for is changes at one end of the dependency (e.g. the database) that can work with two versions of things at the other end of the dependency (e.g. the software). If you can achieve this, then the blue/green, feature flag etc. approaches will work even though the dependency exists.
An example of the choreography is as follows:
- A new column is added to the database that is nullable, i.e. its value is optional. The old version of the software continues to work as before. If it inserts data into the changed table, the new column has the value null. If it reads data from the changed table, it ignores the new column.
- A new version of the software is introduced that knows about the database change. It can set the new column to a non-null value, and make use of the column’s value if it reads the changed table. The new version of the code must cope with the column having a null value.
- Eventually the new version of the software is established as the only version running. At this point we have the option of making the new column non-nullable, i.e. mandatory. The details of this will vary depending on circumstances, but might include an extra bit of code to migrate any remaining null values to a non-null one. Once all rows have a non-null value, the database can be updated to make the column non-nullable.
Databases aren’t the only example of dependencies that matter during upgrades. Things like APIs, file formats for CSV files etc. also need care so that they don’t get in the way of upgrades.
