If you have automated tests for your code, you are doing better than some programmers. However, how good are those tests? In this article I’ll explore how tests can be good (or not).
Cable clip analogy
Before I get into tests, I want to introduce something that will be useful as an analogy for them. If you have had to secure something like an Ethernet cable in your home, you might have used one of these:

They are cable clips. The cable goes under the arch, and then the tack to one side of the arch is hammered e.g. into a wall, holding the cable clip in place. This, in turn, holds the cable in place – the two sides of the arch fit snuggly around the cable and stop it from moving. I think that good tests act as cable clips for your code, holding it securely where you want it to be. It might not be obvious what I mean by that, so I’ll now explore how code and tests fit together.
Boundaries
I’m going to pick a simple example, but I hope you will be able to extrapolate from it to the kind of code you write. Imagine there’s a quantity that’s an integer, and all integers 11 or less are invalid, and all integers 12 or higher are valid. For instance, it could be the number of positive reviews that a product has received, and once it has received enough positive reviews it will be featured on an online shop’s home page.
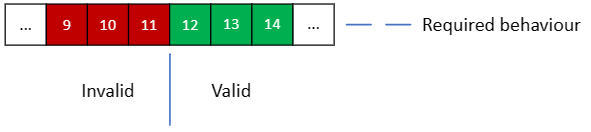
The first test that people would write for this is probably one that makes sure a valid product appears on the home page. This would probably be followed by one that makes sure an invalid product doesn’t appear on the home page. Which values should you pick for those tests?
Loose-fitting tests
It might be tempting to pick nice values for the tests – round numbers or numbers that come to mind easily. A couple of examples for this code are 1 and 100. They will certainly prompt the code to act in the two ways we need it to: the product doesn’t appear on the home page, and the product does.
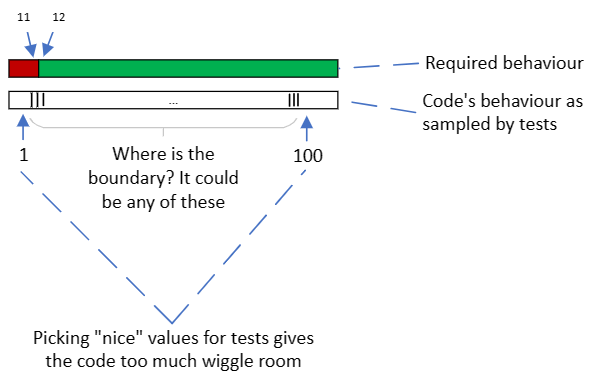
Unfortunately, in this case 1 and 100 are a very loose fit for the code. The tests allow the boundary between invalid and valid to be anywhere between 1 and 100 – the 11/12 boundary certainly falls in this range, but so do many others. The pair of tests is like a very wide cable clip, that allows the cable to wiggle around between the walls of the arch.
If the relevant variable is positiveReviewsCount, then code like this would fit the required behaviour:
if (positiveReviewsCount >= 12)This divides the number line at 11/12. However, the programmer might have accidentally got the comparison wrong:
if (positiveReviewsCount > 12)This divides the number line at 12/13. Tests at 1 and 100 wouldn’t spot this – the product with 1 positive review would still not be on the home page, and the product with 100 would still be on the home page.
Tight-fitting tests
Even though the numbers aren’t as nice, you will get better tests if you use numbers that are at the edges of the regions that the code worries about. In this case, that’s 11 and 12:
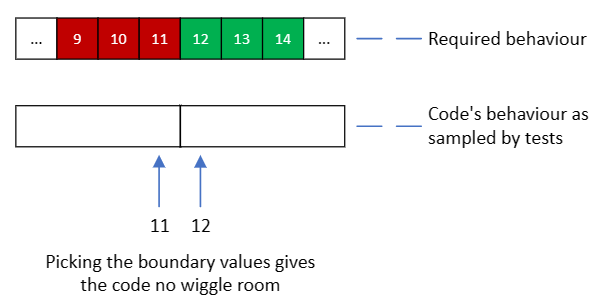
The tests are like a cable clip that’s only just big enough for the cable (the code). There’s no wiggle room, so the code is forced to be exactly where we want it. If the programmer made the same mistake as before, the tests would now fail. The product with 12 positive reviews wouldn’t be on the home page, but the test would expect that it is and so would fail.
Improved clarity
A side effect of tests at the boundary values comes from the fact that tests can be used as documentation for your code. If you pick values like 1 and 100 for the tests, it’s not clear from reading the tests what the code’s behaviour is. However, if the tests use 11 and 12 it makes it much clearer where the boundary is in the code.
If you have existing tests, you might now want to know if you have loose-fitting tests. It can be tedious and error-prone to read through tests and the corresponding code, so I suggest that you use mutation testing to make it clearer where the loose-fitting tests are. Mutation testing will deliberately introduce the kinds of changes I referred to above as the programmer’s mistake, run the related tests and report if they continue to pass (a sign of loose-fitting tests).
